

Q2 2016 saw Backblaze introduce 8TB drives into our drive mix, kick off a Pod to Vault migration of over 6.5PB of data, cross over 250 petabytes of data stored, and deploy another 7,290 drives into the data center for a total of 68,813 spinning hard drives under management. With all the ins and outs, let’s take a look at how our hard drives fared in Q2 2016.
Backblaze Hard Drive Reliability for Q2 2016
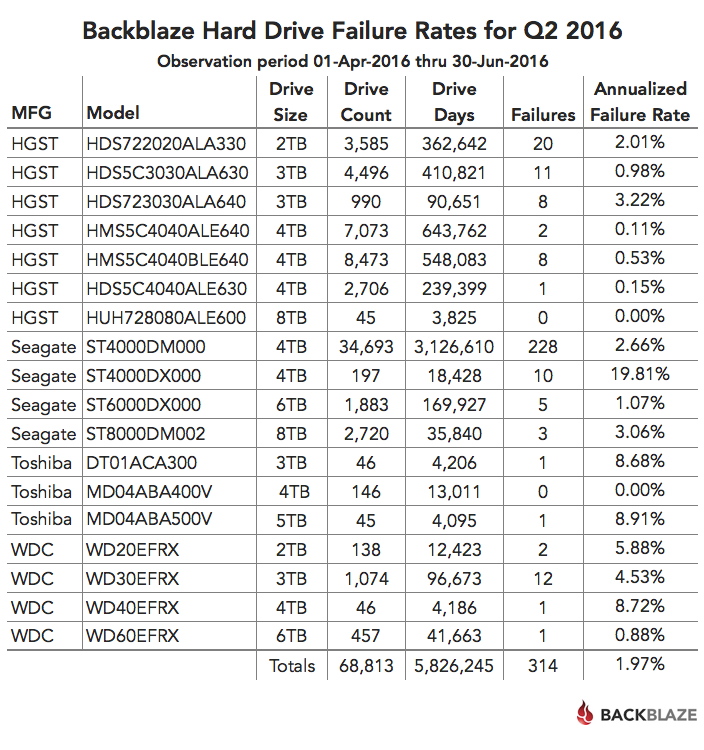
Below is the hard drive failure data for Q2 2016. This chart is just for the period of Q2 2016. The hard drive models listed below are data drives (not boot drives), and we only list models which have 45 or more drives of that model deployed.
 A couple of observations on the chart:
A couple of observations on the chart:
- The models that have an annualized failure rate of 0.00% had zero hard drive failures in Q2 2016.
- The annualized failure rate is computed as follows: ((Failures)/(Drive Days/365)) * 100. Therefore consider the number of failures and drive days before reaching any conclusions about the failure rate.
Later in this post, we’ll review the cumulative statistics for all of our drives over time, but first, let’s take a look at the new drives on the block.
The 8TB Hard Drives Have Arrived
For the last year or so we kept saying we were going to deploy 8TB drives in quantity. We did deploy 45 8TB HGST drives, but deploying these drives en masse did not make economic sense for us. Over the past quarter, 8TB drives from Seagate became available at a reasonable price, so we purchased and deployed over 2,700 in Q2 with more to come in Q3. All of these drives were deployed in Backblaze Vaults with each Vault using 900 drives, that’s 45 drives in each of the 20 Storage Pods that form a Backblaze Vault.
Yes, we said 45 drives in each Storage Pod, so what happened to our 60 drive Storage Pods? In short, we wanted to use the remaining stock of 45 drive Storage Pods before we started using the 60 drive Pods. We have built two Backblaze Vaults using the 60 drive Pods, but we filled them with 4TB and 6TB drives. The first 60 drive Storage Pod filled with 8TB drives (total 480TB) will be deployed shortly.
Hard Drive Migration—85 Pods to One Vault
One of the reasons that we made the move to 8TB drives was to optimize storage density. We’ve done data migrations before, for example, from 1TB Pods to 3TB and 4TB Pods. These migrations were done one or two Storage Pods at a time. It was time to up our game. We decided to migrate from individual Storage Pods filled with HGST 2TB drives, average age 64 months, to a Backblaze Vault filled with 900 8TB drives.

We identified and tagged 85 individual Storage Pods to migrate from. Yes, 85. The total amount of data to be migrated was about 6.5PB. It was a bit sad to see the 2TB HGST drives go as they have been really good over the years, but getting four times as much data into the same space was just too hard to resist.
The first step is to stop all data writes on the donor HGST 2TB Storage Pods. We then kicked off the migration by starting with 10 Storage Pods. We then added 10 to 20 donor Pods to the migration every few hours until we got to 85 Pods. The migration process is purposely slow as we want to ensure that we can still quickly read files from the 85 donor Pods so that data restores are not impacted. The process is to copy a given RAID-array from a Storage Pod to a specific Tome in a Backblaze Vault. Once all the data in a given RAID-array has been copied to a Tome, we move on to the next RAID-array awaiting migration and continue the process. This happens in parallel across the 45 Tomes in a Backblaze Vault.
We’re about 50% of the way through the migration with little trouble. We did have a Storage Pod in the Backblaze Vault go down. That didn’t stop the migration, as Vaults are designed to continue to operate under such conditions, but more on that in another post.
250 Petabytes of Data Stored
Recently we took a look at the growth of data and the future of cloud storage. Given the explosive growth in data as a whole, it’s not surprising that Backblaze added another 50PB of customer data over the last two quarters and that by mid-June we had passed the 250PB mark in total data stored. You can see our data storage growth below:
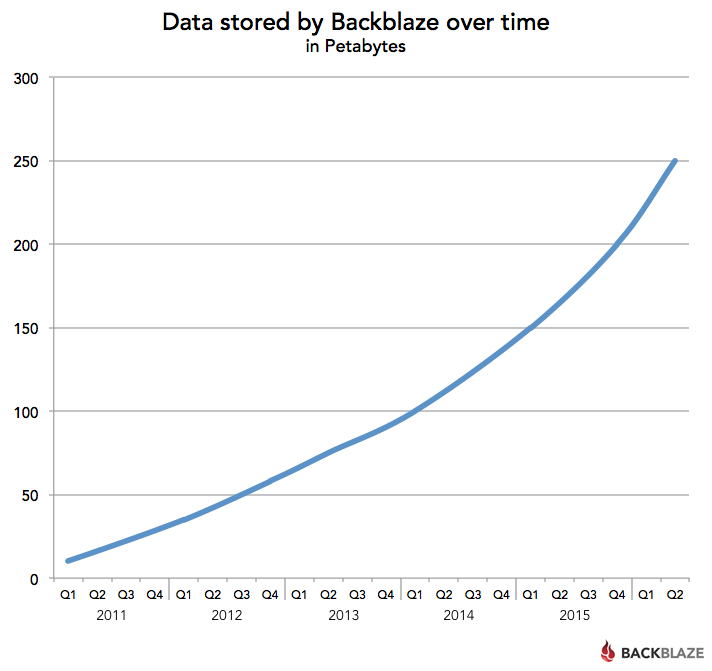
Back in December 2015, we crossed over the 200PB mark and at that time predicted we would cross 250PB in early Q3 2016. So, we’re a few weeks early. We also predicted we would cross 300PB in late 2016. Given how much data we are adding with Backblaze B2, it will probably be sooner; we’ll see.
Cumulative Hard Drive Failure Rates by Model
In the table below, we’ve computed the annualized drive failure rate for each drive model. This is based on data from April 2013 through June 2016.
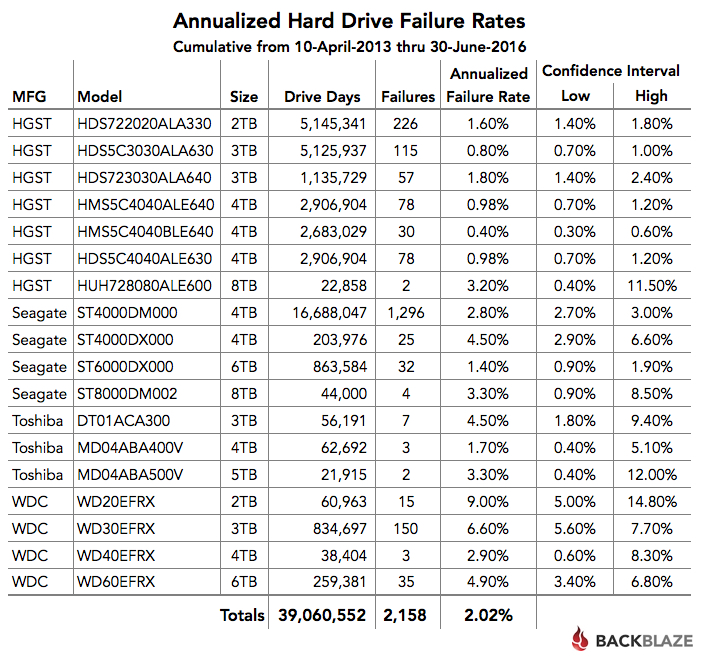
Some people question the usefulness of the cumulative annualized failure rate. This is usually based on the idea that drives entering or leaving during the cumulative period skew the results because they are not there for the entire period. This is one of the reasons we compute the annualized failure rate using drive days. A drive day is only recorded if the drive is present in the system. For example, if a drive is installed on July 1st and fails on August 31st, it adds 62 drive days and one drive failure to the overall results. A drive can be removed from the system because it fails, or perhaps it is removed from service after a migration, like the 2TB HGST drives we’ve covered earlier. In either case, the drive stops adding drive days to the total, allowing us to compute an annualized failure rate over the cumulative period based on what each of the drives contributed during that period.
As always, we’ve published the Q2 2016 data we used to compute these drive stats. You can find the data files along with the associated documentation on our hard drive test data page.
Which Hard Drives Do We Use?
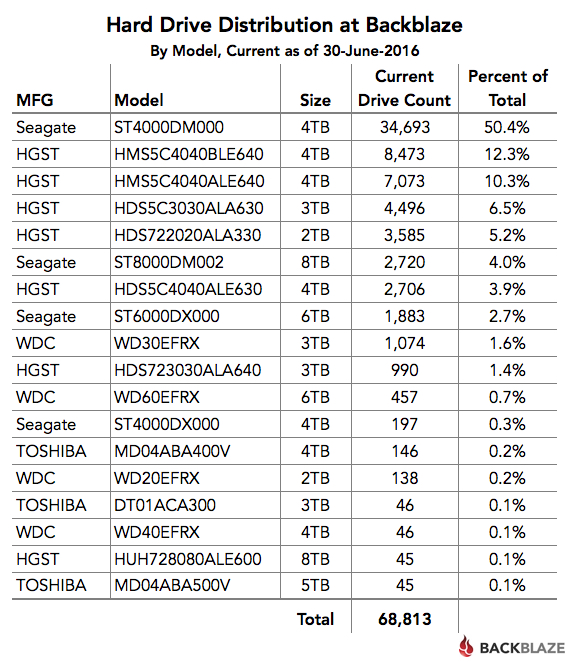
We’ve written previously about our difficulties in getting drives from Toshiba and Western Digital. Whether it’s poor availability or an unexplained desire not to sell us drives, we don’t have many drives from either manufacturer. So we use a lot of Seagate drives and they are doing the job very nicely. The table below shows the distribution of the hard drives we are currently using in our data center.
Recap
The Seagate 8TB drives are here and are looking good. Sadly we’ll be saying goodbye to the HGST 2TB drives, but we need the space. We’ll miss those drives, they were rock stars for us. The 4TB Seagate drives are our workhorse drives today and their 2.8% annualized failure rate is more than acceptable for us. Their low failure rate roughly translates to an average of one drive failure per Storage Pod per year. Over the next few months, expect more on our migrations, a look at the day in the life of a data center tech, and an update of the bathtub curve, i.e. hard drive failure over time.


