

We recently installed and deployed 45 HGST 8TB hard drives into Backblaze Storage Pod 902 and the drives have recently completed their initial data loading phase. As we have done with Seagate, Western Digital, and Toshiba drives, we tracked the HGST drives during their data loading phase to see how well they performed. Here’s what we know so far.
Helium Drives
The HGST 8TB drives are filled with helium. According to the HGST literature, the helium-filled environment lets the disks spin more easily, as helium offers less resistance versus air. This means less power is required to spin the disks and they run cooler. It also means they can have more disks and read/write heads with the HGST 8TB drive having seven platters in a similar space as other drives.
The amount of helium in a drive is not published, but it is tracked as SMART attribute 22, with both the raw and normalized values starting at 100. During our period of observation, the value of these attributes did not change.
A 360TB Backblaze Storage Pod
We filled Storage Pod 902 with 45 HGST 8TB drives. That created our very first 360TB Storage Pod. If we built out a rack of 10 Pods, we would have 3.6PB of storage in one full height rack. That would be awesome, but it won’t happen yet—more on that later in this post.
For the moment, let’s look at how the HGST 8TB drives in Storage Pod 902 performed versus our current data load test champ, the Toshiba 5TB drives in Storage Pod 909. As always, we tracked the Storage Pods until they were 80% full of data.
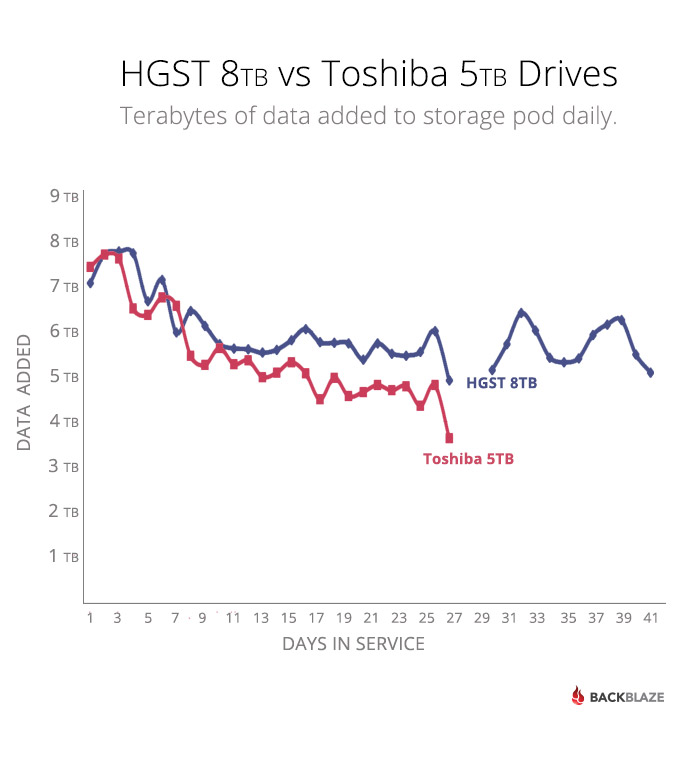
A New Data Load Test Champion
A Storage Pod with Toshiba 5TB drives took 26 days to reach 80% capacity and loaded data at an average rate of 5.46TB per day. The Storage Pod with HGST 8TB drives took 40 days to reach 80% capacity and loaded data at a rate of 5.66TB per day. Given both Pods are similarly configured and both drives are 7200 rpm drives, perhaps there is something to using helium after all. Regardless, the HGST 8TB drives are our current data load test champion as Storage Pod 902 loaded, on average, 5.66TB of data per day.
You might be wondering about the two days in the chart above on the HGST data line where it appears no data was written to the Storage Pod. That was caused by a drive failure. Yes, one of the 45 HGST 8TB drives failed in the middle of our observation period. The drive was replaced a short time after it failed, but no data was loaded for two days; why? Let’s walk through the process of when a drive fails.
- Our monitoring system reports that a drive has gone offline in Pod 902.
- Pod 902 is flipped into maintenance mode. This places the Pod in read only mode, letting any current write operations complete, then only allowing read operations.
- Once the Pod is in maintenance mode, a Backblaze data center technician uses the monitoring system to evaluate the issue looking to determine if it is just a drive failure or something more. Depending on the failure, the drive can be restarted, but most often the drive is dead. That was the case in Pod 902. At this point, the drive is scheduled for replacement.
- Depending on workload and the time of day, the failed drive is replaced anywhere from a few minutes to a few hours later. The Pod continues to operate in read-only mode during that time.
- To replace the drive, the data center technician suspends new read operations, then shuts down the Storage Pod.
- The technician locates the Storage Pod and slides it out of the rack. They open the Pod, locate the dead drive, confirm it is the failed drive using the serial number, replace the drive, and then close up the Pod. This typically takes three to five minutes.
- Once the Pod is back in the rack, it is restarted. The replaced drive is then synced into its RAID array. This can take anywhere from a few hours to a couple of days depending on the size of the drive. During this time, the Pod remains in maintenance mode, meaning it is read-only.
- Once the new drive sync is complete, the Pod is placed back into full service. This was the case with Pod 902 and it continued loading data after being in maintenance (read-only) mode for about 49 hours.
By the way, in a Backblaze Vault, when a drive fails it will cause zero downtime for reading or writing even as the data center technician goes through the steps outlined above. This is one of the reasons for migrating from individual Storage Pods to the Backblaze Vault architecture.
It should be noted that the two days that Storage Pod 902 was not receiving new data is part of the 40 total days it took to reach the 80% full benchmark. If you were to subtract those two days, then the average amount of data loaded per day would be 5.96TB per days for the 38 days the Pod was able to receive data. Where, oh where, should the asterisks be?
More HGST 8TB drives?
There are many things to like about the HGST 8TB drives: the low power requirements, high storage capacity, and five year warranty lead the list. Currently, the lowest street price we’ve found is $547.99 on Amazon with some sites asking for as much as $795 for each drive. Using street prices, let’s compare the cost per gigabyte of the HGST to the different drives we currently use most often:
| Street Price of Hard Drives Used at Backblaze | ||||||||
|---|---|---|---|---|---|---|---|---|
| Drive Type/Size | Street Price | Cost/GB | ||||||
| HGST 8TB | $547.99 | $0.068 | ||||||
| Seagate 6TB | $239.99 | $0.040 | ||||||
| Seagate 4TB | $152.00 | $0.038 | ||||||
| HGST 4TB | $162.72 | $0.041 | ||||||
The cost per terabyte of the HGST 8TB drive is currently about 1.6 times more expensive than the drives we are currently purchasing. While the HGST 8TB drive is an enterprise class drive, the premium we’d have to pay doesn’t make sense for us, especially as we move to Backblaze Vaults where individual drive failures have zero effect on downtime. Yes, we’ve built and placed into production a 360TB Storage Pod, but it will be at least a few months before we build the next one while we wait for the cost per terabyte of the 8TB drives to come down. Or maybe we’ll just wait for the newly announced HGST 10TB drives—perhaps HGST will loan us 45 drives for a few years so we can test them…


