
A lot has changed in the four years since Brian Beach wrote a post announcing Backblaze Vaults, our software architecture for cloud data storage. Just looking at how the major statistics have changed, we now have over 100,000 hard drives in our data centers instead of the 41,000 mentioned in the post video. We have three data centers (soon four) instead of one data center. We’re approaching one exabyte of data stored for our customers (almost seven times the 150 petabytes back then), and we’ve recovered over 41 billion files for our customers, up from the 10 billion in the 2015 post.
In the original post, we discussed having durability of seven nines. Shortly thereafter, it was upped to eight nines. In July of 2018, we took a deep dive into the calculation and found our durability closer to eleven nines (and went into detail on the calculations used to arrive at that number). And, as followers of our Hard Drive Stats reports will be interested in knowing, we’ve just started testing our first 16 TB drives, which are twice the size of the biggest drives we used back at the time of this post — then a whopping eight TB.
We’ve updated the details here and there in the text from the original post that was published on our blog on March 11, 2015. We’ve left the original 135 comments intact, although some of them might be non sequiturs after the changes to the post. We trust that you will be able to sort out the old from the new and make sense of what’s changed. If not, please add a comment and we’ll be happy to address your questions.
— Editor
Storage Vaults form the core of Backblaze’s cloud services. Backblaze Vaults are not only incredibly durable, scalable, and performant, but they dramatically improve availability and operability, while still being incredibly cost-efficient at storing data. Back in 2009, we shared the design of the original Storage Pod hardware we developed; here we’ll share the architecture and approach of the cloud storage software that makes up a Backblaze Vault.
Backblaze Vault Architecture for Cloud Storage
The Vault design follows the overriding design principle that Backblaze has always followed: keep it simple. As with the Storage Pods themselves, the new Vault storage software relies on tried and true technologies used in a straightforward way to build a simple, reliable, and inexpensive system.
A Backblaze Vault is the combination of the Backblaze Vault cloud storage software and the Backblaze Storage Pod hardware.
Putting The Intelligence in the Software
Another design principle for Backblaze is to anticipate that all hardware will fail and build intelligence into our cloud storage management software so that customer data is protected from hardware failure. The original Storage Pod systems provided good protection for data and Vaults continue that tradition while adding another layer of protection. In addition to leveraging our low-cost Storage Pods, Vaults take advantage of the cost advantage of consumer-grade hard drives and cleanly handle their common failure modes.
Distributing Data Across 20 Storage Pods
A Backblaze Vault is comprised of 20 Storage Pods, with the data evenly spread across all 20 pods. Each Storage Pod in a given vault has the same number of drives, and the drives are all the same size.
Drives in the same drive position in each of the 20 Storage Pods are grouped together into a storage unit we call a tome. Each file is stored in one tome and is spread out across the tome for reliability and availability.
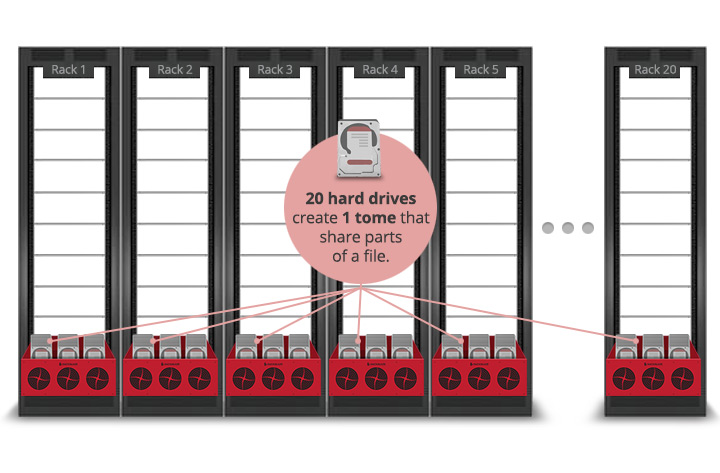
Every file uploaded to a Vault is divided into pieces before being stored. Each of those pieces is called a shard. Parity shards are computed to add redundancy, so that a file can be fetched from a vault even if some of the pieces are not available.
Each file is stored as 20 shards: 17 data shards and three parity shards. Because those shards are distributed across 20 Storage Pods, the Vault is resilient to the failure of a Storage Pod.
Files can be written to the Vault when one pod is down and still have two parity shards to protect the data. Even in the extreme and unlikely case where three Storage Pods in a Vault lose power, the files in the vault are still available because they can be reconstructed from any of the 17 pods that are available.
Storing Shards
Each of the drives in a Vault has a standard Linux file system, ext4, on it. This is where the shards are stored. There are fancier file systems out there, but we don’t need them for Vaults. All that is needed is a way to write files to disk and read them back. Ext4 is good at handling power failure on a single drive cleanly without losing any files. It’s also good at storing lots of files on a single drive and providing efficient access to them.
Compared to a conventional RAID, we have swapped the layers here by putting the file systems under the replication. Usually, RAID puts the file system on top of the replication, which means that a file system corruption can lose data. With the file system below the replication, a Vault can recover from a file system corruption because a single corrupt file system can lose at most one shard of each file.
Creating Flexible and Optimized Reed-Solomon Erasure Coding
Just like RAID implementations, the Vault software uses Reed-Solomon erasure coding to create the parity shards. But, unlike Linux software RAID, which offers just one or two parity blocks, our Vault software allows for an arbitrary mix of data and parity. We are currently using 17 data shards plus three parity shards, but this could be changed on new vaults in the future with a simple configuration update.

For Backblaze Vaults, we threw out the Linux RAID software we had been using and wrote a Reed-Solomon implementation from scratch, which we wrote about in “Backblaze Open-sources Reed-Solomon Erasure Coding Source Code.” It was exciting to be able to use our group theory and matrix algebra from college.
The beauty of Reed-Solomon is that we can then re-create the original file from any 17 of the shards. If one of the original data shards is unavailable, it can be re-computed from the other 16 original shards, plus one of the parity shards. Even if three of the original data shards are not available, they can be re-created from the other 17 data and parity shards. Matrix algebra is awesome!
Handling Drive Failures
The reason for distributing the data across multiple Storage Pods and using erasure coding to compute parity is to keep the data safe and available. How are different failures handled?
If a disk drive just up and dies, refusing to read or write any data, the Vault will continue to work. Data can be written to the other 19 drives in the tome, because the policy setting allows files to be written as long as there are two parity shards. All of the files that were on the dead drive are still available and can be read from the other 19 drives in the tome.

When a dead drive is replaced, the Vault software will automatically populate the new drive with the shards that should be there; they can be recomputed from the contents of the other 19 drives.
A Vault can lose up to three drives in the same tome at the same moment without losing any data, and the contents of the drives will be re-created when the drives are replaced.
Handling Data Corruption
Disk drives try hard to correctly return the data stored on them, but once in a while they return the wrong data, or are just unable to read a given sector.
Every shard stored in a Vault has a checksum, so that the software can tell if it has been corrupted. When that happens, the bad shard is recomputed from the other shards and then re-written to disk. Similarly, if a shard just can’t be read from a drive, it is recomputed and re-written.
Conventional RAID can reconstruct a drive that dies, but does not deal well with corrupted data because it doesn’t checksum the data.
Scaling Horizontally
Each vault is assigned a number. We carefully designed the numbering scheme to allow for a lot of vaults to be deployed, and designed the management software to handle scaling up to that level in the Backblaze data centers.
The overall design scales very well because file uploads (and downloads) go straight to a vault, without having to go through a central point that could become a bottleneck.
There is an authority server that assigns incoming files to specific Vaults. Once that assignment has been made, the client then uploads data directly to the Vault. As the data center scales out and adds more Vaults, the capacity to handle incoming traffic keeps going up. This is horizontal scaling at its best.
We could deploy a new data center with 10,000 Vaults holding 16TB drives and it could accept uploads fast enough to reach its full capacity of 160 exabytes in about two months!
Backblaze Vault Benefits
The Backblaze Vault architecture has six benefits:
1. Extremely Durable
The Vault architecture is designed for 99.999999% (eight nines) annual durability (now 11 nines — Editor). At cloud-scale, you have to assume hard drives die on a regular basis, and we replace about 10 drives every day. We have published a variety of articles sharing our hard drive failure rates.
The beauty with Vaults is that not only does the software protect against hard drive failures, it also protects against the loss of entire Storage Pods or even entire racks. A single Vault can have three Storage Pods — a full 180 hard drives — die at the exact same moment without a single byte of data being lost or even becoming unavailable.
2. Infinitely Scalable
A Backblaze Vault is comprised of 20 Storage Pods, each with 60 disk drives, for a total of 1200 drives. Depending on the size of the hard drive, each vault will hold:
12TB hard drives => 12.1 petabytes/vault (Deploying today.)
14TB hard drives => 14.2 petabytes/vault (Deploying today.)
16TB hard drives => 16.2 petabytes/vault (Small-scale testing.)
18TB hard drives => 18.2 petabytes/vault (Announced by WD & Toshiba)
20TB hard drives => 20.2 petabytes/vault (Announced by Seagate)
At our current growth rate, Backblaze deploys one to three Vaults each month. As the growth rate increases, the deployment rate will also increase. We can incrementally add more storage by adding more and more Vaults. Without changing a line of code, the current implementation supports deploying 10,000 Vaults per location. That’s 160 exabytes of data in each location. The implementation also supports up to 1,000 locations, which enables storing a total of 160 zettabytes (also known as 160,000,000,000,000 GB)!

3. Always Available
Data backups have always been highly available: if a Storage Pod was in maintenance, the Backblaze online backup application would contact another Storage Pod to store data. Previously, however, if a Storage Pod was unavailable, some restores would pause. For large restores this was not an issue since the software would simply skip the Storage Pod that was unavailable, prepare the rest of the restore, and come back later. However, for individual file restores and remote access via the Backblaze iPhone and Android apps, it became increasingly important to have all data be highly available at all times.
The Backblaze Vault architecture enables both data backups and restores to be highly available.
With the Vault arrangement of 17 data shards plus three parity shards for each file, all of the data is available as long as 17 of the 20 Storage Pods in the Vault are available. This keeps the data available while allowing for normal maintenance and rare expected failures.
4. Highly Performant
The original Backblaze Storage Pods could individually accept 950 Mbps (megabits per second) of data for storage.
The new Vault pods have more overhead, because they must break each file into pieces, distribute the pieces across the local network to the other Storage Pods in the vault, and then write them to disk. In spite of this extra overhead, the Vault is able to achieve 1,000 Mbps of data arriving at each of the 20 pods.

This capacity required a new type of Storage Pod that could handle this volume. The net of this: a single Vault can accept a whopping 20 Gbps of data.
Because there is no central bottleneck, adding more Vaults linearly adds more bandwidth.
5. Operationally Easier
When Backblaze launched in 2008 with a single Storage Pod, many of the operational analyses (e.g. how to balance load) could be done on a simple spreadsheet and manual tasks (e.g. swapping a hard drive) could be done by a single person. As Backblaze grew to nearly 1,000 Storage Pods and over 40,000 hard drives, the systems we developed to streamline and operationalize the cloud storage became more and more advanced. However, because our system relied on Linux RAID, there were certain things we simply could not control.
With the new Vault software, we have direct access to all of the drives and can monitor their individual performance and any indications of upcoming failure. And, when those indications say that maintenance is needed, we can shut down one of the pods in the Vault without interrupting any service.
6. Astoundingly Cost Efficient
Even with all of these wonderful benefits that Backblaze Vaults provide, if they raised costs significantly, it would be nearly impossible for us to deploy them since we are committed to keeping our online backup service affordable for completely unlimited data. However, the Vault architecture is nearly cost neutral while providing all these benefits.

When we were running on Linux RAID, we used RAID6 over 15 drives: 13 data drives plus two parity. That’s 15.4% storage overhead for parity.
With Backblaze Vaults, we wanted to be able to do maintenance on one pod in a vault and still have it be fully available, both for reading and writing. And, for safety, we weren’t willing to have fewer than two parity shards for every file uploaded. Using 17 data plus three parity drives raises the storage overhead just a little bit, to 17.6%, but still gives us two parity drives even in the infrequent times when one of the pods is in maintenance. In the normal case when all 20 pods in the Vault are running, we have three parity drives, which adds even more reliability.
Summary
Backblaze’s cloud storage Vaults calculated at 99.999999% (eight nines) annual durability (now 11 nines — Editor), horizontal scalability, and 20 Gbps of per-Vault performance, while being operationally efficient and extremely cost effective. Driven from the same mindset that we brought to the storage market with Backblaze Storage Pods, Backblaze Vaults continue our singular focus of building the most cost-efficient cloud storage available anywhere.
• • •
Note: This post was updated from the original version posted on March 11, 2015.


