

On April 10, 2013, Backblaze saved our first daily hard drive snapshot file. We had decided to start saving these daily snapshots to improve our understanding of the burgeoning collection of hard drives we were using to store customer data. That was the beginning of the Backblaze Drive Stats reports that we know today.
Little did we know at the time that we’d be collecting the data for the next 10 years or writing various Drive Stats reports that are read by millions, but here we are.
I’ve been at Backblaze longer than Drive Stats and probably know the drive stats data and history better than most, so let’s spend the next few minutes getting beyond the quarterly and lifetime tables and charts and I’ll tell you some stories from behind the scenes of Drive Stats over the past 10 years.
1. The Drive Stats Light Bulb Moment
I have never been able to confirm whose idea it was to start saving the Drive Stats data. The two Brians—founder Brian Wilson, our CTO before he retired and engineer Brian Beach, our current CTO—take turns eating humble pie and giving each other credit for this grand experiment.
But, beyond the idea, one Brian or the other also had to make it happen. Someone had to write the Python scripts to capture and process the data, and then deploy these scripts across our fleet of shiny red Storage Pods and other storage servers, and finally someone also had to find a place to store all this newly captured data. My money’s on—to paraphrase Mr. Edison—founder Brian being the 1% that is inspiration, and engineer Brian being the 99% that is perspiration. The split could be 90/10 or even 80/20, but that’s how I think it went down.
2. The Experiment Begins
In April 2013, our Drive Stats data collection experiment began. We would collect and save basic drive information, including the SMART statistics for each drive, each day. The effort was more than a skunkworks project, but certainly not a full-fledged engineering project. Conducting such experiments has been part of our DNA since we started and we continue today, albeit with a little more planning and documentation. Still the basic process—try something, evaluate it, tweak it, and try again—still applies, and over the years, such experiments have led to the development of our Storage Pods and our Drive Farming efforts.
Our initial goal in collecting the Drive Stats data was to determine if it would help us better understand the failure rates of the hard drives we were using to store data. Questions that were top of mind included: Which drive models lasted longer? Which SMART attributes really foretold drive health? What is the failure rate of different models? And so on. The answers, we hoped, would help us make better purchasing and drive deployment decisions.
3. Where “Drive Days” Came From
To compute a failure rate of a given group of drives over a given time period, you might start with two pieces of data: the number of drives, and the number of drive failures over that period of time. So, if over the last year, you had 10 drives and one failed, you could say the 10% failure rate for the year. That works for static systems, but data centers are quite different. On a daily basis, drives enter and leave the system. There are new drives, failed drives, migrated drives, and so on. In other words, the number of drives is probably not consistent across a given time period. To address this issue, CTO Brian (current CTO Brian that is) worked with professors from UC Santa Cruz on the problem and the idea of Drive Days was born. A drive day is one drive in operation for one day, so one drive in operation for ten days is ten drive days.
To see this in action you start by defining the cohort of drives and the time period you want and then apply the following formula to get the Annualized Failure Rate (AFR).
AFR = ( Drive Failures / ( Drive Days / 365 ) )
This simple calculation allows you to compute an Annualized Failure Rate for any cohort of drives over any period of time and accounts for a variable number of drives over that period.
4. Wait! There’s No Beginning?
In testing out our elegantly simple AFR formula, we discovered a problem. Not with the formula, but with the data. We started collecting data on April 10, 2013, but many of the drives were present before then. If we wanted to compute the AFR of model XYZ for 2013, we could not count the number of drive days those drives had prior to April 10—there were none.
Never fear, SMART 9 raw value to the rescue. For the uninitiated, the SMART 9 raw value contains the number of power-on hours for a drive. A little math gets you the number of days—that is Drive Days—and you are ready to go. This little workaround was employed whenever we needed to work with drives that came into service before we started collecting data.
Why not use SMART 9 all of the time? A couple of reasons. First, sometimes the value gets corrupted. Especially when the drive is failing, it could be zero or a million or anywhere in between. Second, a new drive can have non-default SMART values. Perhaps it is just part of the burn in process or a test group at the manufacturer, or maybe the drive was a return that passed some qualification process.
Regardless, the starting value of SMART 9 wasn’t consistent across drives, so we just counted operational days in our environment and used SMART 9 as a substitute only when we couldn’t count those days. Using SMART 9 is moot now as these days there are no drives left in the current drive collection which were present prior to April 2013.
5. There’s Gold In That There Data
While the primary objective of collecting the data was to improve our operations, there was always another potential use lurking about—to write a blog post, or two, or 56. Yes, we’ve written 56 blog posts and counting based on our Drive Stats data. And no, we could have never imagined that would be the case when this all started back in 2013.
The very first Drive Stats-related blog post was written by Brian Beach (current CTO Brian, former engineer Brian) in November 2013 (we’ve updated it since then). The post had the audacious title of “How Long Do Disk Drives Last?” and a matching URL of “www.backblaze.com/blog/how-long-do-disk-drives-last/”. Besides our usual blog readers, search engines were falling all over themselves referring new readers to the site based on searches for variants of the title and the post became first page search material for multiple years. Alas, all Google things must come to an end, as the post disappeared into page two and then the oblivion beyond.
Buoyed by the success of the first post, Brian went on to write several additional posts over the next year or so based on the Drive Stats data.
- December 2013: Enterprise Drives: Fact or Fiction?
- January 2014: What Hard Drive Should I Buy?
- May 2014: Hard Drive Temperature—Does It Matter?
- September 2014: Hard Drive Reliability Update: September 2014
- November 2014: Hard Drive SMART Stats
- January 2015: What Is the Best Hard Drive?
- February 2015: Reliability Data Set for 41,000 Hard Drives Now Open-Source
That’s an impressive body of work, but Brian is, by head and heart, an engineer, and writing blog posts meant he wasn’t writing code. So after his post to open source the Drive Stats data in February 2015, he passed the reins of this nascent franchise over to me.
6. What’s in a Name?
When writing about drive failure rates, Brian used the term “Hard Drive Reliability” in his posts. When I took over, beginning with the Q1 2015 report, we morphed the term slightly to “Hard Drive Reliability Stats.” That term lasted through 2015 and in Q1 2016 it was shortened to “Hard Drive Stats.” I’d like to tell you there was a great deal of contemplation and angst that went into the decision, but the truth is the title of the Q1 2016 post “One Billion Drive Hours and Counting: Q1 2016 Hard Drive Stats,” was really long and we left out the word reliability so it wouldn’t be any longer—something about title length, the URL, search terms, and so on. The abbreviated version stuck and to this day we publish “Hard Drive Stats” reports. That said, we often shorten the term even more to just “Drive Stats,” which is technically more correct given we have solid state drives (SSDs), not just hard disk drives (HDDs), in the dataset when we talk about boot drives.
7. Boot Drives
Beginning in Q4 2013, we began collecting and storing failure and SMART stats data from some of the boot drives that we use on our storage servers in the Drive Stats data set. Over the first half of 2014, additional boot drive models were configured to report their data and by Q3 2014, all boot drives were reporting. Now the Drive Stats dataset contained both data from the data drives and the boot drives of our storage servers. There was one problem: there was no field for drive source. In other words, to distinguish a data drive from a boot drive, you needed to use the drive model.
In Q4 2018, we began using SSDs as boot drives and began collecting and storing drive stats data from the SSDs as well. Guess what? There was no drive type field either, so SSD and HDD boot drives had to be distinguished by their model numbers. Our engineering folks are really busy on product and platform features and functionality, so we use some quick-and-dirty SQL on the post-processing side to add the missing information.
The boot drive data sat quietly in the Drive Stats dataset for the next few years until Q3 2021 when we asked the question “Are SSDs Really More Reliable Than Hard Drives?” That’s the first time the boot drive data was used. In this case, we compared the failure rates of SSDs and HDDs over time. As the number of boot drive SSDs increased, we started publishing a semi-annual report focused on just the failure rates for the SSD boot drives.
8. More Drives = More Data
On April 10, 2013, data was collected for 21,195 hard drives. The .csv data file for that day was 3.2MB. The numbers of drives and the amount of data has grown just a wee bit since then, as you can see in the following charts.
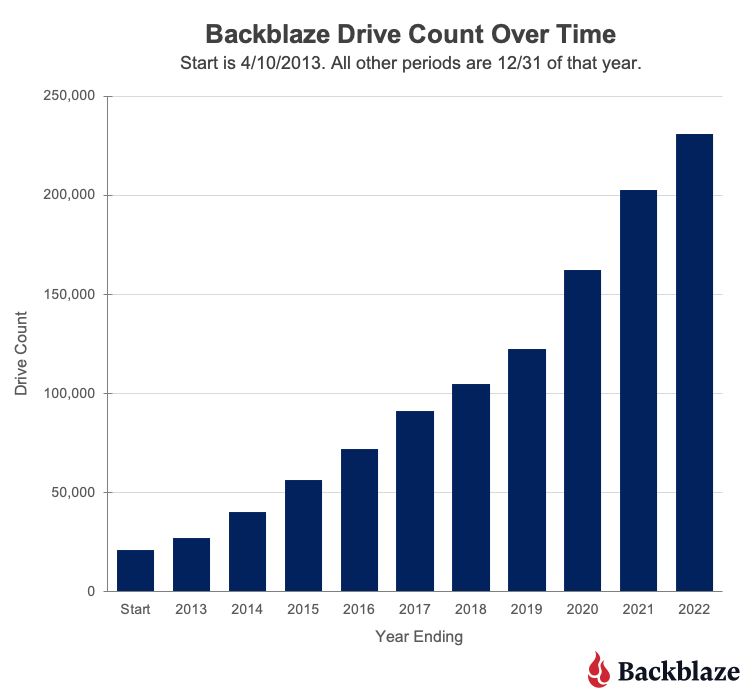
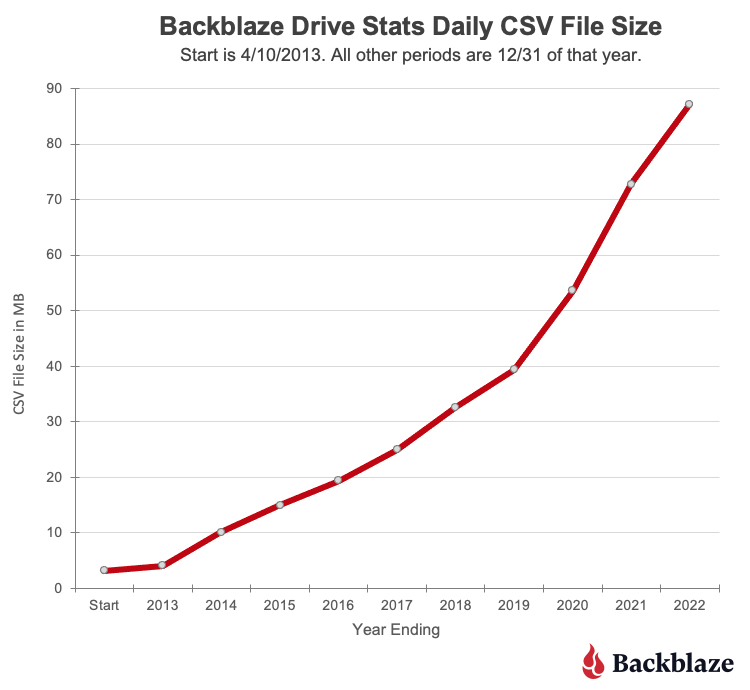
The current size of a daily Drive Stats .csv file is over 87MB. If you downloaded the entire Drive Stats dataset, you would need 113GB of storage available once you unzipped all the data files. If you are so inclined, you’ll find the data on our Drive Stats page. Once there, open the “Downloading the Raw HD Test Data” link to see a complete list of the files available.
9. Who Uses The Drive Stats Dataset?
Over the years, the Drive Stats dataset has been used in multiple ways for different reasons. Using Google Scholar, you can currently find 660 citations for the term “Backblaze hard drive stats” going back to 2014. This includes 18 review articles. Here are a couple of different ways the data has been used.
-
-
- As a teaching tool: Several universities and similar groups have used the dataset as part of their computer science, data analytics, or statistics classes. The dataset is somewhat large, but it’s still manageable, and can be divided into yearly increments if needed. In addition, it is reasonably standardized, but not perfect, providing a good data cleansing challenge. The different drive models and variable number of drive counts allows students to practice data segmentation across the various statistical methods they are studying.
- For artificial intelligence (AI) and machine learning: Over the years several studies have been conducted using AI and machine learning techniques applied to the Drive Stats data to determine if drive failure or drive health is predictable. We looked at one method from Interpretable on our blog, but there are several others. The results have varied, but the general conclusion is that while you can predict drive failure to some degree, the results seem to be limited to a given drive model.
-
10. Drive Stats Experiments at Backblaze
Of course, we also use the Drive Stats data internally at Backblaze to inform our operations and run our own experiments. Here are a couple examples:
-
-
- Inside Backblaze: Part of the process in developing and productizing the Backblaze Storage Pod was the development of the software to manage the system itself. Almost from day one, we used certain SMART stats to help determine if a drive was not feeling well. In practice, other triggers such as ATA errors or FSCKs alerts, will often provide the first indicator of a problem. We then apply the historical and current SMART stats data that we have recorded and stored to complete the analysis. For example, we receive an ATA error on a given drive. There could be several non-drive reasons for such an error, but we can quickly determine that the drive has a history of increasing bad media and command timeouts values over time. Taken together, it could be time to replace that drive.
- Trying new things: The Backblaze Evangelism team decided that SQL was too slow when accessing the Drive Stats data. They decided to see if they could use a combination of Parquet and Trino to make the process faster. Once they had done that, they went to work duplicating some of the standard queries we run each quarter in producing our Drive Stats Reports.
-
What Lies Ahead
First, thank you for reading and commenting on our various Drive Stats Reports over the years. You’ve made us better and we appreciate your comments—all of them. Not everyone likes the data or the reports, and that’s fine, but most people find the data interesting and occasionally useful. We publish the data as a service to the community at large, and we’re glad many people have found it helpful, especially when it can be used in teaching people how to test, challenge, and comprehend data—a very useful skill in navigating today’s noise versus knowledge environment.
We will continue to gather and publish the Drive Stats dataset each quarter for as long as it is practical and useful to our readers. That said, I can’t imagine we’ll be writing Drive Stats reports 10 years from now, but just in case, if anyone is interested in taking over, just let me know.


