

As you’re sitting down to watch yet another episode of “Mystery Science Theater 3000” (Anyone else? Just me?), you might be thinking about how you’re receiving more than 16 billion signals over your home internet connection that need to be interpreted and sent to decoding software in order to be viewed on a screen as images. (Anyone else? Just me?)
In telecommunications, we study how signals (electrical and optical) propagate in a medium (copper wires, optical fiber, or through the air). Signals bounce off objects, degrade as they travel, and arrive at the receiving end (hopefully) intact enough to be interpreted as a binary 0 or 1, eventually to be decoded to form images that we see on our screens.
Today in the latest installment of Network Stats, I’m going to talk about one of the most important things that I’ve learned about the application of telecommunication to computer networks: the study of how long operations take. It’s a complicated process, but that doesn’t make buffering any less annoying, am I right? And if you’re using cloud storage in any way, you rely on signals to run applications, back up your data, and maybe even stream out those movies yourself.
So, let’s get into how we measure data transmission, what things we can do to improve transmission time, and some real-world measurements from the Backblaze US-West region.
Networking and Nanoseconds: A Primer
At the risk of being too basic, when we study network communication, we’re measuring how long signals take to get from point A to point B, which implies that there is some amount of distance between them. This is also known as latency. As networks have evolved, the time it takes to get from point A to point B has gone from being measured in hours to being measured in fractions of a second. Since we live in more human relatable terms like minutes, hours, and days, it can be hard for us to understand concepts like nanoseconds (a billionth of a second).
Here’s a breakdown of how many milli, micro, and nanoseconds are in one second.
| Time | Symbol | Number in 1 Second |
|---|---|---|
| 1 second | 1 | |
| 1 millisecond | ms | 1,000 |
| 1 microsecond | μs | 1,000,000 |
| 1 nanosecond | ns | 1,000,000,000 |
For reference, taking a deep breath takes approximately one second. When you’re watching TV, you start to notice audio delays at approximately 10–20ms, and if your cat pushes your pen off your desk, it will hit the ground in approximately 400ms.
Nanosecond Wire: Making Nanoseconds Real
In the 1960s, Grace Murray Hopper (1906–1992) explained computer operations and what a nanosecond means in a succinct, tangible fashion. An early computer scientist who also served in the U.S. Navy, Hopper was often asked by folks like generals and admirals why it took so long for signals to reach satellites. So, Hopper had pieces of wire cut to 30cm (11.8in) in length, which is the distance that it takes light to travel in perfect conditions—that is, a vacuum—in one nanosecond. (Remember: we humans express speed as distance over time.)
You could touch the wire, feel the distance from point A to point B, and see what a nanosecond in light-time meant. Put a bunch of them together, and you’d see what that looks like on a human scale. In literal terms, she was forcing people to measure the distance to a satellite (anywhere between 160–35,786 km) in terms of the long side of a piece of printer paper. (Rough math: it’s about 741,058,823 to 1,657,529,411,764 pieces of paper end-to-end.) That’ll definitely make you realize that there are a lot of nanoseconds between you and the next city over or a satellite in space.
A fun side note: if we go up a factor from a nanosecond to a microsecond, the wire would be almost 300 meters (984 feet)—which is the height of the Eiffel Tower, minus the broadcast antennae. It gets even more fun to think about because we still have to scale up to two more orders of magnitude to get to a millisecond, and then again to get a second.

I love when a difficult topic can be grasped with an elegant explanation. It’s one of the skills that I strive to develop as an engineer—how can I relate a complicated concept to a larger audience that doesn’t have years of study in my field, and make it easily digestible and memorable?
Added Application Time
We don’t live in an ideal, perfect vacuum where signals can propagate in a line-of-sight fashion and travel in an optimal path. We have wires in buildings and in the ground that wind around metro regions, follow long-haul railroad tracks as they curve, and have to pass over hills and along mountainous terrain that add elevation to the wire length, all adding light-time.
These physical factors are not the only component in the way of receiving your data. There are computer operations that add time to our transactions. We have to send a “hello” message to the server and wait for an acknowledgement, negotiate our security protocols so that we can transmit data without anyone snooping in on the conversation, spend time receiving the bytes that make up our file, and acknowledge chunks of information as received so the server can send more.
How much do geography and software operations add to the time it takes to get a file? That’s what we’re going to explore here. So, if we’re requesting a file that’s stored on Backblaze’s servers in the US-West region, what does that look like if we are delivering the file to different locations across the continental U.S.? How long does it take?
Building a Latency Test
Today we’re going to focus on network statistics for our US-West location and how the performance profile looks as we travel east and the various components that contribute to the change in translation time.
Below we’re going to compare theoretical best case numbers to the real world. There are three categories in our analysis that contribute to the total time it takes to get a request from a person in Los Angeles, Chicago, or New York, to our servers in the US-West region. Let’s take a look at each one:
- Ideal Line: Let’s draw an imaginary line between our US-West location and each major city in our testing sample. Then we can calculate the time it takes light to be sent and received as RTT (Round Trip Time) one time between the two points. This number gives us the Ideal Line time, or the time it takes for a light signal to travel between two points in a perfect line, in vacuum conditions, with no obstructions. Hardly how we live, so we have to add a few other data points!
- Fiber: Fiber optics in the real world have to pass through optical equipment, connect to aerial fiber on telephone poles where ground access is limited, route around pesky obstructions like mountains or municipal services, and sometimes travel along non-ideal paths to reach major connection points where long-haul fiber providers have offices to improve and reamplify the signal. This RTT number is taken from testing services that we have running across the country.
- Software: This measurement shows the time spent in Software tasks (as opposed to Setup or Download tasks, as defined by Google) that are required to initiate network connections, negotiate mutual settings between sender and receiver, wait for data to start to be received, and encrypt/decrypt messages. We’re also getting this number from our testing services and will explore all the inner workings of the Software components a little later on.
- Total: The interesting part! Real world RTT for retrieving a sample file from various locations.
Fun fact: You don’t need any monitoring infrastructure in order to take a deeper dive—every Chrome web browser has the ability to show load times for all the elements that are needed to present a website.
Do note that test results may vary based on your ISP connectivity, hardware capabilities, software stack, or improvements Backblaze makes over time.
To show more detailed information, open Chrome:
- Go to Chrome Options > More Tools > Developer Tools
- Select Network Tab
- Browse to a website to see results sourced from your machine
A deeper dive into this can be found on Google’s developer.chrome.com website.
If you wish to run agent based tests, you can start with Google’s Chromium Project, as it offers a free and open source method to simulate and perform profiling.
Here are the results from just one test we ran:
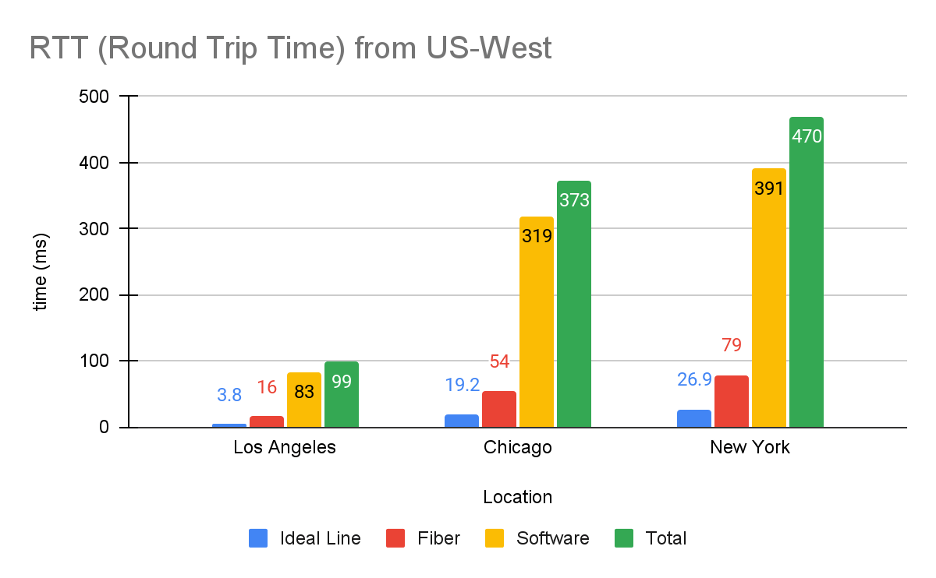
It’s important, at this stage, to caveat these numbers with a few things. First, they include a decent amount of overhead from being within our (or any) infrastructure, which can be affected by things like your browser, security, and lookup time needed to connect to a server infrastructure. And, if a user is running a different browser, has different layers of security, and so on, those things can affect RTT results.
Second, they don’t accurately talk about performance without context. Every type of application has its own requirements for what is a “good” or “bad” RTT time, and these numbers can change based on how you store your data; where you store, access, and serve your data; if you use a content delivery network (CDN); and more. As with anything related to performance in cloud storage, your use case determines your cloud storage strategy, not the other way around.
Unpacking the Software Measurement
In addition to the Chrome tools we talk about above, we have access to agents running in various geographical locations across the world that run periodic tests to our services. These agents can simulate client activity and record metrics for us that we use for alerting and trend analysis. Simulating client operations helps alert our operations teams to potential issues, helping us to better support our clients and be more proactive.
With this type of agent based testing, we have greater insight into the network that lets us break down the Software step and observe if any one step in the transfer pipeline is underperforming. We’re not only looking at the entire round trip time of downloading a file, but also including all the browser, security, and lookup time needed to connect to our server infrastructure. And, as always, the biggest addition in time it takes to deliver files is often distance-based latency, or the fact that even with ideal conditions, the further away an end user is, the longer it takes to transport data across networks.
Unpacking Software Results
The below chart shows how long in milliseconds it takes to get a sample file from our US-West cluster from agents running in different locations across the U.S. and all the Software steps involved.
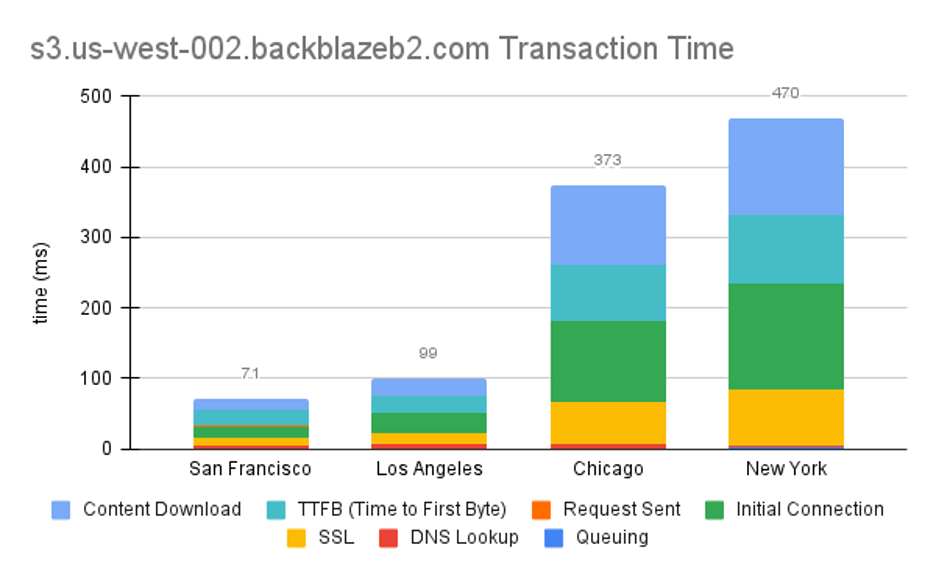
You can find definitions for all these terms in the Chromium dev docs, but here’s a cheat sheet for our purposes:
- Queueing: Browser queues up connection.
- DNS Lookup: Resolving the request’s IP address.
- SSL: Time spent negotiating a secure session.
- Initial Connection: TCP handshake.
- Request Sent: This is pretty self explanatory—the request is sent to the server.
- TTFB (Time to First Byte): Waiting for the first byte of a response. Includes one round trip of latency and the time the server took to prepare the response.
- Content Download: Total amount of time receiving the requested file.
Pie Slices
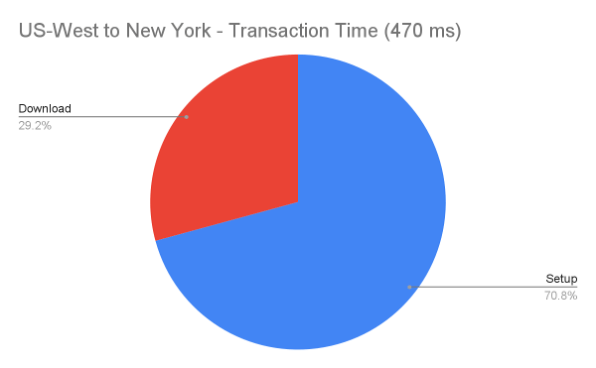
Let’s zoom in on the Los Angeles and New York tests and group just the Download (Content Download) and all the other Setup items (Queueing, DNS Lookup, SSL, Initial Connection, TTFB) and see if they differ drastically.
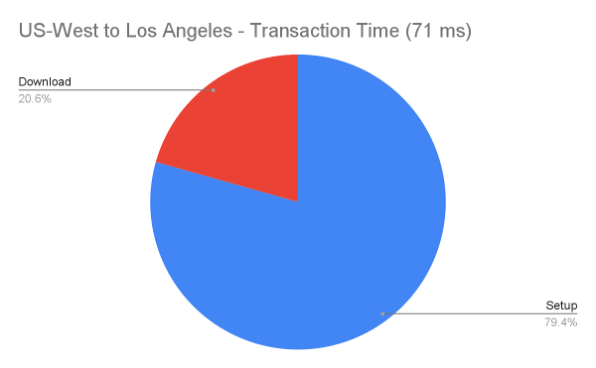
In the Los Angeles test, which is the closest geographical test to the US-West cluster, the total transaction time is 71ms. It takes our storage system 23.8ms to start to send the file, and we’re spending 47ms (66%) of the total time in setup.
If we go further east to New York, we can see how much more time it takes to retrieve our test file from the West (71ms vs 470ms), but the ratio between download and setup doesn’t differ all that drastically. This is because all of our operations are the same, but we’re spending more sending each file over the network, so it all scales up.
Note that no matter where the client request is coming from, the data center is doing the same amount of work to serve up the file.
Customer Considerations: The Importance of Location in Data Storage
Latency is certainly a factor to consider when you choose where to store your data, especially if you are running extremely time sensitive processes like content delivery—as we’ve noted here and elsewhere, the closer you are to your end user, the greater the speed of delivery. Content delivery networks (CDNs) can offer one way to layer your network capabilities for greater speed of delivery, and Backblaze offers completely free egress through many CDN partners. (This is in addition to our normal amount of free egress, which is up to 3x the data stored and includes the vast majority of use cases.)
There are other reasons to consider different regions for storage as well, such as compliance and disaster resilience. Our EU datacenter, for instance, helps to support GDPR compliance. Also, if you’re storing data in only one location, you’re more vulnerable to natural disasters. Redundancy is key to a good disaster recovery or business continuity plan, and you want to make sure to consider power regions in that analysis. In short, as with all things in storage optimization, considering your use case is key to balancing performance and cost.
Milliseconds Matter
I started this article talking about Grace Murray Hopper demonstrating nanoseconds with pieces of wire, and we’re concluding what can be considered light years (ha) away from that point. The biggest thing to remember, as a network engineering team, is that even though approximately 600ms from the US-West to the US-East regions seems miniscule, the amount of times we travel that distance very quickly takes us up those orders of magnitude from milliseconds to seconds. And, when you, the user, are choosing where to store your data—knowing that we register audio lag at as little as 10ms—those inconsequential numbers start to get to human relative terms very, very quickly.
So, when we find that peering shaves a few milliseconds off of a file delivery time, that’s a big, human-sized win. You can see some of the ways we’re optimizing our network in the first article of this series, and the types of tests we’re running above give us good insights—and inspiration—for more, better, and ongoing improvements. We’ll keep sharing what we’re measuring and how we’re improving, and we’re looking forward to seeing you all in the comments.


