

Bandwidth purchased for data center connectivity surged by nearly 330% between 2020 and 2024, driven primarily by AI workloads. And in 2024, just 10 buyers accounted for nearly 62% of all purchases, according to Zayo’s Bandwidth Report. That concentration is a structural feature of how AI moves data.
Every training run that pulls data from Backblaze storage to a neocloud passes through our network, and our telemetry captures what those flows look like in real time. Our Q4 2025 Network Stats report covers a full quarter of that data. It shows AI workloads producing a distinct network signature: sustained, high-volume transfers between a small number of endpoints, with infrastructure requirements specific enough to be worth examining in detail.
This piece walks through what that signature looks like and what it means for the infrastructure decisions teams are making right now.
The AI model lifecycle and how it moves data
AI model development is a cycle. Large datasets are ingested and consolidated, exported to compute for training, pulled back for evaluation, then pushed out again as models are refined, retrained, and updated with new data. Each stage requires moving substantial volumes of data between storage and compute, repeatedly, over the life of a model.

That structure produces a specific kind of network traffic. AI training moves petabyte-scale data between storage and compute nodes in sustained, long-lived flows—what network engineers call elephant flows—with training jobs running for hours or days under continuous network load. Add frequent checkpointing, model updates, and periodic data refreshes, and the result is traffic that is high in volume and persistent across the entire training run.
This shows up clearly in the Q4 2025 Network Stats data. Neocloud traffic spiked sharply from July through November, peaking in October, then settled into a higher baseline heading into the new year. One interpretation of that shape is the AI lifecycle playing out across a concentration of large training cycles: ingestion, training egress, then a new steady state as stored models get served and periodically retrained. As we accumulate more quarters of data across a broader customer mix, we’ll be better positioned to distinguish that pattern from seasonal budget cycles or customer-specific factors.
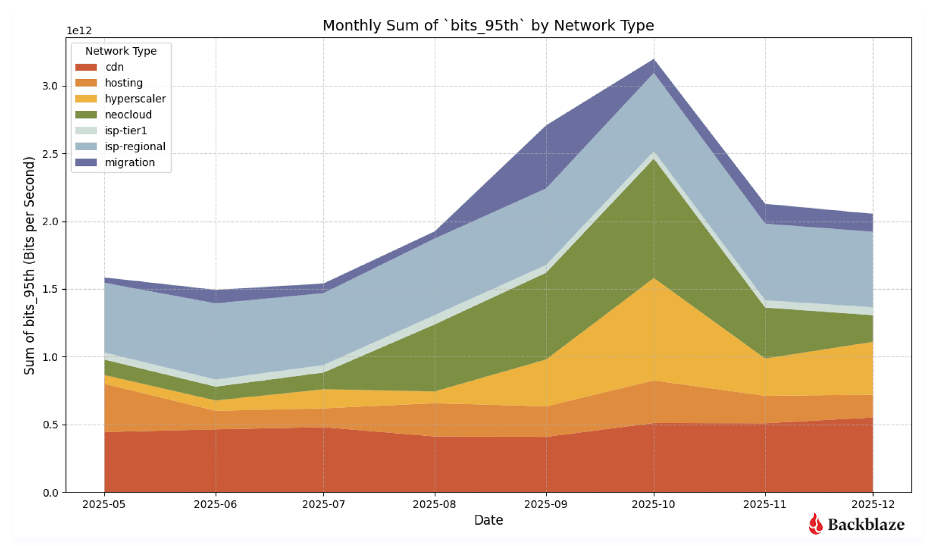
Also visible in the Q4 data is where this traffic is going. Cloud-to-cloud traffic grew from 36.2% to 49.6% quarter-over-quarter, with hyperscaler destinations rising from 3.5% to 18%. As the report notes, it’s too early to call these statistically significant trends; the dataset reflects Backblaze’s specific customer mix and covers a single quarter. The direction is consistent with how AI teams operate in practice: moving workloads across neoclouds and hyperscalers depending on price, availability, and job requirements. The storage layer is what persists across those compute environments, which has direct implications for how it needs to be designed.
What elephant flows require from a network
Traditional cloud infrastructure is designed around a specific traffic profile: many clients, many sessions, many discrete transactions. Routing, load balancing, and edge capacity are all optimized for that pattern, distributing load broadly and handling high volumes of short-lived connections efficiently.
Elephant flows don’t fit that profile. AI training establishes persistent, high-volume connections between client and storage that sustain continuous data movement for hours or days at a time. These connections are stickier than typical cloud traffic, particularly on peered networks, and the strain they produce is concentrated rather than distributed—showing up primarily at the edge, where routers handle sustained throughput at scale. Most traditional cloud infrastructure wasn’t provisioned for that kind of sustained pressure at the edge, because most workloads don’t produce it. Internal to the network, depending on a myriad of things—object size, concurrent threads, hardware, internal routing logic—your network path being sticky doesn’t reduce the number of I/O operations for servers, and often that becomes one of the biggest bottlenecks.
The stakes make this consequential. Training the most advanced models now costs hundreds of millions of dollars, according to Epoch AI—though we also know this is a new technology, and therefore likely the compute will get more efficient over time. That said, the storage is still storage: Data has to live somewhere.
Infrastructure that can’t sustain throughput under continuous load doesn’t just slow training down; it adds cost to every run. The practical answer is building throughput capacity at the connection points between storage infrastructure and the internet or peer network, sized for sustained flows rather than peak bursts.
That’s what AI-grade storage infrastructure is designed around: sustained throughput to a small number of destinations, at 100Gbps to 1Tbps per transfer for the largest AI workflows. Achieving that in practice means rethinking how a network is designed, routed, and scaled. We’ve written separately about what that looked like for Backblaze’s own infrastructure. Latency matters here for a specific reason: on long-distance transfers, higher latency directly limits achievable sustained throughput, which is one reason why geographic proximity to compute infrastructure affects real-world performance.
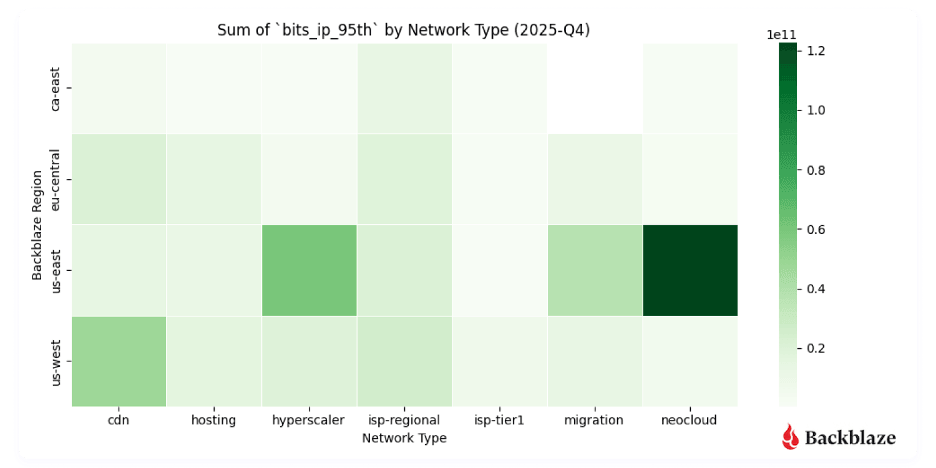
The Q4 Network Stats heatmaps show this pattern from two angles. The magnitude heatmap, measuring bits transferred per unique IP address, shows high-magnitude neocloud flows clustering clearly in regions serving AI-heavy compute endpoints. The uniqueness heatmap shows neocloud traffic involving fewer, more persistent endpoints than CDN or ISP traffic, consistent with AI pipelines that rely on stable, long-standing connections between storage and compute.
The geography of AI infrastructure
The heatmaps show where AI traffic concentrates geographically today. Neocloud activity in the Q4 dataset clusters in Chicago, Dallas-Houston, Denver, New York, the Northern Virginia Reston/Ashburn corridor, and Atlanta, with a clear skew toward the East Coast. This reflects where AI compute infrastructure was built first and remains densest. Keeping latency low between storage and compute is a prerequisite for sustaining the high throughput rates AI workflows require, and that constraint has historically made East Coast proximity an advantage.
That concentration is consistent with broader infrastructure dynamics. AI training workloads are driving demand for regions with available power, fiber density, and compute infrastructure, and power constraints in preferred markets are already forcing operators to explore secondary locations and invest in custom power infrastructure. Demand in markets outside traditional data center hubs is growing rapidly as a result: Metro bandwidth in Memphis grew from 0.3 terabits to 13.2 terabits between 2023 and 2024. On the flip side, building out cabling to those traditionally under-utilized locations is expensive, often adding thousands of dollars per month to data center economics. High-capacity interconnects are central to making those secondary locations viable; without them, the compute investment is stranded.
The scale of what’s being built reflects the trajectory of the workload. AI training infrastructure is projected to grow at a 22% compound annual growth rate (CAGR) through 2030, reaching more than 60GW of capacity, while inference infrastructure is expected to grow faster still at 35% CAGR, reaching more than 90GW, according to McKinsey. Training and inference have different geographic requirements: training tolerates latency and can sit in power-rich remote locations, while inference needs to be close to users, which means the buildout will be distributed across both dense metro markets and secondary locations connected by high-capacity fiber.
Backblaze’s own infrastructure decisions reflect this pattern directly. The East Coast concentration drove the decision to double Backblaze’s US-East footprint. At 100Gbps and above, proximity to where AI compute is actually running is a determining factor in storage performance.
What AI-ready storage infrastructure actually means
Storage has traditionally been sized for capacity and evaluated on cost per terabyte. AI workflows change the calculus. When a training run is pulling petabytes of data from object storage to flash storage at sustained 100Gbps rates, the storage layer is as much a performance determinant as the compute layer. A storage system that can’t sustain those throughput rates creates a bottleneck that no amount of GPU capacity can compensate for.
Throughput capability is one requirement. Portability is the other. The multi-cloud behavior visible in the Q4 data reflects how AI teams actually operate: moving workloads to whichever compute provider offers the best price-performance for a given job. Storage that is tightly coupled to one cloud provider is structurally incompatible with that workflow. Data that can’t move freely across cloud environments becomes a constraint on the model development process.
This is the infrastructure problem Backblaze B2 Overdrive is designed to address. By building a direct, high-performance path between Backblaze’s storage layer and the neoclouds where AI processing takes place, it provides the sustained throughput that training workflows require alongside the portability to move data as compute requirements change. The connections between Backblaze and neocloud endpoints visible in the Q4 heatmaps represent that architecture in practice.
The point extends beyond any single product. As AI workloads become a larger share of overall data center activity, the criteria for evaluating storage infrastructure are shifting. Capacity and cost per terabyte remain relevant, but sustained throughput capability, interoperability with compute providers, and network proximity to AI infrastructure are becoming equally important factors. Teams that treat storage as a passive component in AI pipeline design are likely to find it becomes the active constraint.
Early signal, long trend
The Q4 2025 Network Stats data is one quarter of observations from one storage provider’s network. The patterns it shows—high-magnitude flows to a small number of endpoints, East Coast geographic concentration, rising cloud-to-cloud traffic, a higher baseline heading into the new year—are consistent with what the broader industry understands about how AI moves data. What’s new is that they’re visible in real network telemetry rather than modeled projections.
We’ll be watching how neocloud traffic concentration evolves regionally, how the training-to-inference ratio shifts as inference infrastructure scales, and whether the cloud-to-cloud growth visible this quarter continues.
The full dataset, methodology, and visualizations are in the Q4 2025 Network Stats report. For background on how we classify and measure network traffic, the Q3 2025 report covers the dataset in detail, and you can follow the whole series here.


