
What do two billion transactions a day look like? Well, the data may be invisible to the naked eye, but the math breaks down to just over 23,000 transactions every second. (Shout out to Kris Allen for burning into my memory that there are 86,400 seconds in a day and my handy calculator!)
Part of my job as a Site Reliability Engineer (SRE) at Backblaze is making sure that greater than 99.9% of those transactions are what we consider “OK” (via status code), and part of the fun is digging for the needle in the haystack of over 7,000 production servers and over 250,000 spinning hard drives to try and understand how all of the different transactions interact with the pieces of infrastructure.
In this blog post, I’m going to pick up where Principal SRE Elliott Sims left off in his 2016 article on load balancing. You’ll notice that the design principles we’ve employed are largely the same (cool!). So, I’ll review our stance on those principles, then talk about how the evolution of the B2 Cloud Storage platform—including the introduction of the S3 Compatible API—has changed our load balancing architecture. Read on for specifics.
Editor’s Note
We know there are a ton of specialized networking terms flying around this article, and one of our primary goals is to make technical content accessible to all readers, regardless of their technical background. To that end, we’ve used footnotes to add some definitions and minimize the disruption to your reading experience.
What Is Load Balancing?
Load balancing is the process of distributing traffic across a network. It helps with resource utilization, prevents overloading any one server, and makes your system more reliable. Load balancers also monitor server health and redirect requests to the most suitable server.
With two billion requests per day to our servers, you can be assured that we use load balancers at Backblaze. Whenever anyone—a Backblaze Computer Backup or a B2 Cloud Storage customer—wants to upload or download data or modify or interact with their files, a load balancer will be there to direct traffic to the right server. Think of them as your trusty mail service, delivering your letters and packages to the correct destination—and using things like zip codes and addresses to interpret your request and get things to the right place.
How Do We Do It?
We build our own load balancers using open-source tools. We use layer 4 load balancing with direct server response (DSR). Here are some of the resources that we call on to make that happen:
- Border gateway protocol (BGP) which is part of the Linux kernel1. It’s a standardized gateway protocol that exchanges routing and reachability information on the internet.
- keepalived, an open-source routing software. keepalived keeps track of all of our VIPs2 and IPs3 for each backend server.
- Hard disk drives (HDDs). We use the same drives that we use for other API servers and whatnot, but that’s definitely overkill—we made that choice to save the work of sourcing another type of device.
- A lot of hard work by a lot of really smart folks.
What We Mean by Layers
When we’re talking about layers in load balancing, it’s shorthand for how deep into the architecture your program needs to see. Here’s a great diagram that defines those layers:
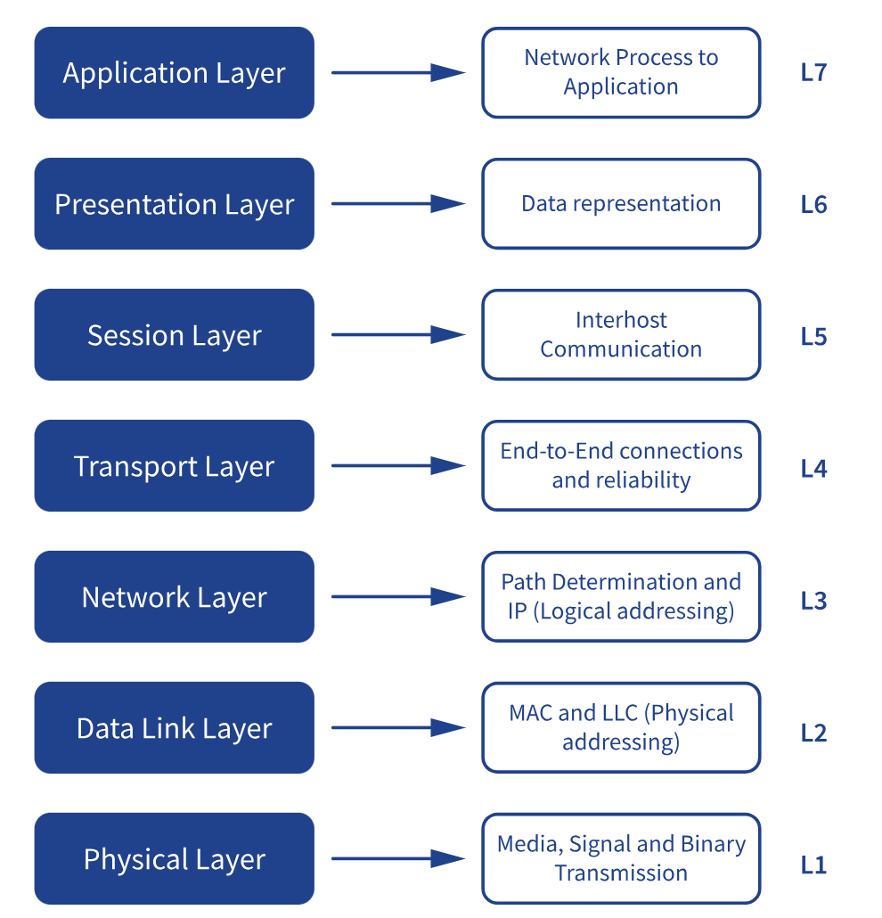
DSR takes place at layer 4, but solves the problem presented by a full proxy4 method, having to see the original client’s IP address.
Why Do We Do It the Way We Do It?
Building our own load balancers, instead of buying an off-the-shelf solution, means that we have more control and insight, more cost-effective hardware, and more scalable architecture. In general, DSR is more complicated to set up and maintain, but this method also lets us handle lots of traffic with minimal hardware and supports our goal of keeping data encrypted, even within our own data center.
What Hasn’t Changed
We’re still using a layer 4 DSR approach to load balancing, which we’ll explain below. For reference, other common methods of load balancing are layer 7, full proxy and layer 4, full proxy load balancing.
First, I’ll explain how DSR works. DSR load balancing requires two things:
- A load balancer with the VIP address attached to an external NIC5 and ARPing6, so that the rest of the network knows it “owns” the IP.
- Two or more servers on the same layer 2 network that also have the VIP address attached to a NIC, either internal or external, but are not replying to ARP requests about that address. This means that no other servers on the network know that the VIP exists anywhere but on the load balancer.
A request packet will enter the network, and be routed to the load balancer. Once it arrives there, the load balancer leaves the source and destination IP addresses intact and instead modifies the destination MAC7 address to that of a server, then puts the packet back on the network. The network switch only understands MAC addresses, so it forwards the packet on to the correct server.
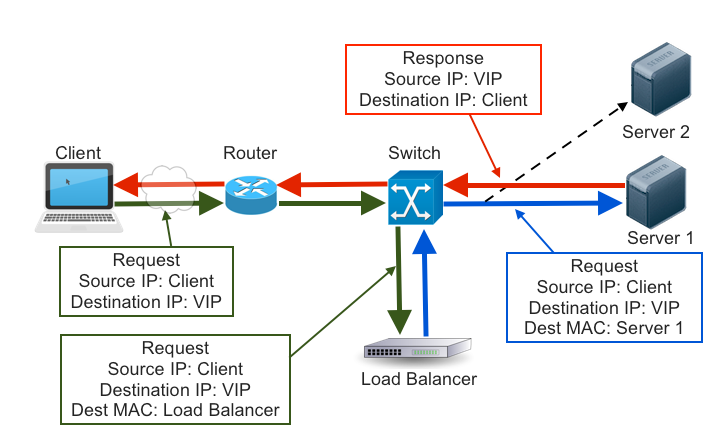
When the packet arrives at the server’s network interface, it checks to make sure the destination MAC address matches its own. The address matches, so the server accepts the packet. The server network interface then, separately, checks to see whether the destination IP address is one attached to it somehow. That’s a yes, even though the rest of the network doesn’t know it, so the server accepts the packet and passes it on to the application. The application then sends a response with the VIP as the source IP address and the client as the destination IP, so the request (and subsequent response) is routed directly to the client without passing back through the load balancer.
So, What’s Changed?
Lots of things. But, since we first wrote this article, we’ve expanded our offerings and platform. The biggest of these changes (as far as load balancing is concerned) is that we added the S3 Compatible API.
We also serve a much more diverse set of clients, both in the size of files they have and their access patterns. File sizes affect how long it takes us to serve requests (larger files = more time to upload or download, which means an individual server is tied up for longer). Access patterns can vastly increase the amount of requests a server has to process on a regular, but not consistent basis (which means you might have times that your network is more or less idle, and you have to optimize appropriately).

Where You Can See the Changes: ECMP, Volume of Data Per Month, and API Processing
DSR is how we send data to the customer—the server responds (sends data) directly to the request (client). This is the equivalent of going to the post office to mail something, but adding your home address as the return address (so that you don’t have to go back to the post office to get your reply).
Given how our platform has evolved over the years, things might happen slightly differently. Let’s dig in to some of the details that affect how the load balancers make their decisions—what rules govern how they route traffic, and how different types of requests cause them to behave differently. We’ll look at:
- Equal cost multipath routing (ECMP).
- Volume of data in petabytes (PBs) per month.
- APIs and processing costs.
ECMP
One thing that’s not explicitly outlined above is how the load balancer determines which server should respond to a request. At Backblaze, we use stateless load balancing, which means that the load balancer doesn’t take into account most information about the servers it routes to. We use a round robin approach—i.e. the load balancers choose between one of a few hosts, in order, each time they’re assigning a request.
We also use Maglev, so the load balancers use consistent hashing and connection tracking. This means that we’re minimizing the negative impact of unexpected faults failures from connection-oriented protocols. If a load balancer goes down, its server pool can be transferred to another, and it will make decisions in the same way, seamlessly picking up the load. When the initial load balancer comes back online, it already has a connection to its load balancer friend and can pick up where it left off.
The upside is that it’s super rare to see a disruption, and it essentially only happens when the load balancer and the neighbor host go down in a short period of time. The downside is that the load balancer decision is static. If you have “better” servers for one reason or another—they’re newer, for instance—they don’t take that information into account. On the other hand, we do have the ability to push more traffic to specific servers through ECMP weights if we need to, which means that we have good control over a diverse fleet of hardware.
Volume of Data
Backblaze now has over three exabytes of storage under management. Based on the scalability of the network design, that doesn’t really make a huge amount of difference when you’re scaling your infrastructure properly. What can make a difference is how people store and access their data.
Most of the things that make managing large datasets difficult from an architecture perspective can also be silly for a client. For example: querying files individually (creating lots of requests) instead of batching or creating a range request. (There may be a business reason to do that, but usually, it makes more sense to batch requests.)
On the other hand, some things that make sense for how clients need to store data require architecture realignment. One of those is just a sheer fluctuation of data by volume—if you’re adding and deleting large amounts of data (we’re talking hundreds of terabytes or more) on a “shorter” cycle (monthly or less), then there will be a measurable impact. And, with more data stored, you have the potential for more transactions.
Similarly, if you need to retrieve data often, but not regularly, there are potential performance impacts. Most of them are related to caching, and ironically, they can actually improve performance. The more you query the same “set” of servers for the same file, the more likely that each server in the group will have cached your data locally (which means they can serve it more quickly).
And, as with most data centers, we store our long term data on hard disk drives (HDDs), whereas our API servers are on solid state drives (SSDs). There are positives and negatives to each type of drive, but the performance impact is that data at rest takes longer to retrieve, and data in the cache is on a faster SSD drive on the API server.
On the other hand, the more servers the data center has, the lower the chance that the servers can/will deliver cached data. And, of course, if you’re replacing large volumes of old data with new on a shorter timeline, then you won’t see the benefits. It sounds like an edge case, but industries like security camera data are a great example. While they don’t retrieve their data very frequently, they are constantly uploading and overwriting their data, often to meet different industry requirements about retention periods, which can be challenging to allocate a finite amount of input/output operations per second (IOPS) for uploads, downloads, and deletes.
That said, the built-in benefit of our system is that adding another load balancer is (relatively) cheap. If we’re experiencing a processing chokepoint for whatever reason—typically either a CPU bottleneck or from throughput on the NIC—we can add another load balancer, and just like that, we can start to see bits flying through the new load balancer and traffic being routed amongst more hosts, alleviating the choke points.
APIs and Processing Costs
We mentioned above that one of the biggest changes to our platform was the addition of the S3 Compatible API. When all requests were made through the B2 Native API, the Backblaze CLI tool, or the web UI, the processing cost was relatively cheap.
That’s because of the way our upload requests to the Backblaze Vaults are structured. When you make an upload request via the Native API, there are actually two transactions, one to get an upload URL, and the second to send a request to the Vault. And, all other types of requests (besides upload) have always had to be processed through our load balancers. Since the S3 Compatible API is a single request, we knew we would have to add more processing power and load balancers. (If you want to go back to 2018 and see some of the reasons why, here’s Brian Wilson on the subject—read with the caveat that our current Tech Doc on the subject outlines how we solve the complications he points out.)
We’re still leveraging DSR to respond directly to the client, but we’ve significantly increased the amount of transactions that hit our load balancers, both because it has to take on more of the processing during transit and because, well, lots of folks like to use the S3 Compatible API and our customer base has grown by a quite a bit since 2018.
And, just like above, we’ve set ourselves up for a relatively painless fix: we can add another load balancer to solve most problems.
Do We Have More Complexity?
This is the million dollar question, solved for a dollar: how could we not? Since our first load balancing article, we’ve added features, complexity, and lots of customers. Load balancing algorithms are inherently complex, but we (mostly Elliott and other smart people) have taken a lot of time and consideration to not just build a system that will scale to up and past two billion transactions a day, but that can be fairly “easily” explained and doesn’t require a graduate degree to understand what is happening.
But, we knew it was important early on, so we prioritized building a system where we could “just” add another load balancer. The thinking is more complicated at the outset, but the tradeoff is that it’s simple once you’ve designed the system. It would take a lot for us to outgrow the usefulness of this strategy—but hey, we might get there someday. When we do, we’ll write you another article.


