

Beginning in January 2012, Backblaze deployed 4,829 Seagate 3TB hard drives, model ST3000DM001, into Backblaze Storage Pods. In our experience, 80% of the hard drives we deploy will function at least four years. As of March 31, 2015, just 10% of the Seagate 3TB drives deployed in 2012 are still in service. This is the story of the 4,345 Seagate 3TB drives that are no longer in service.
November 2011: The Thailand Drive Crisis
In November 2011, Backblaze, like everyone else who used hard drives, was reeling from the effects of the Thailand drive crisis. Prices had jumped 200-300% for hard drives and supplies were tight. The 3TB drives we normally used from HGST (formerly Hitachi) were difficult to find, but we still needed to buy 500-600 drives a month to run our online backup business. The 3TB drives we were able to find in decent quantity were from Seagate and we bought as many as we could. We purchased internal drives and also external USB drives, from which we removed the enclosed hard drive. The model number of the drive, ST3000DM001, was the same for both the internal and external drives.
Here is a chart of our Seagate drive purchases from November 2011 through December 2012.
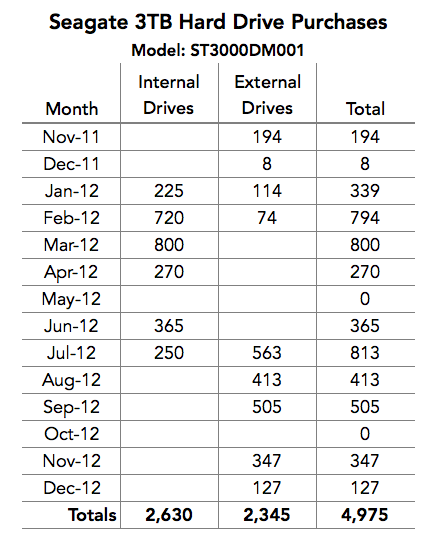
Our New Reality in the Face of the Thailand Drive Crisis
Looking back on 2012, it is safe to say that if we did not purchase the Seagate 3TB drives, our business would have been dramatically affected. We estimated that our costs would have been at least $1.14 million more, making our goal of keeping our price at $5/month for unlimited storage difficult, at best. In other words, the ability to purchase, at a reasonable price, the nearly 5,000 Seagate 3TB drives that we needed during 2012 was instrumental in meeting our business objectives.
Beginning in January 2012, we deployed 4,829 Seagate 3TB drives as shown below.
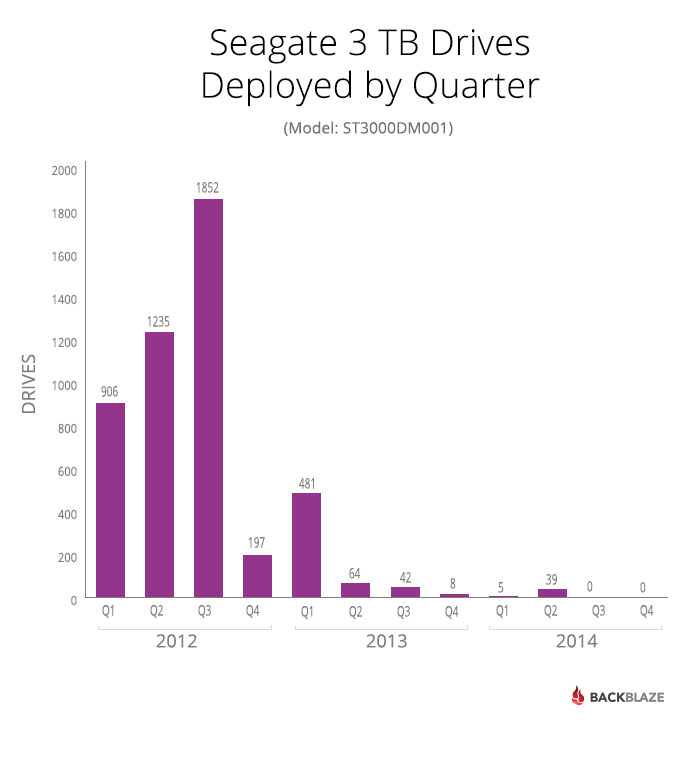
The Slide to Failure
We would expect the Seagate 3TB drives to follow the bathtub-shaped failure rate curve described in our study on hard drive life expectancy. Instead, the Seagate drives failure model was quite different.
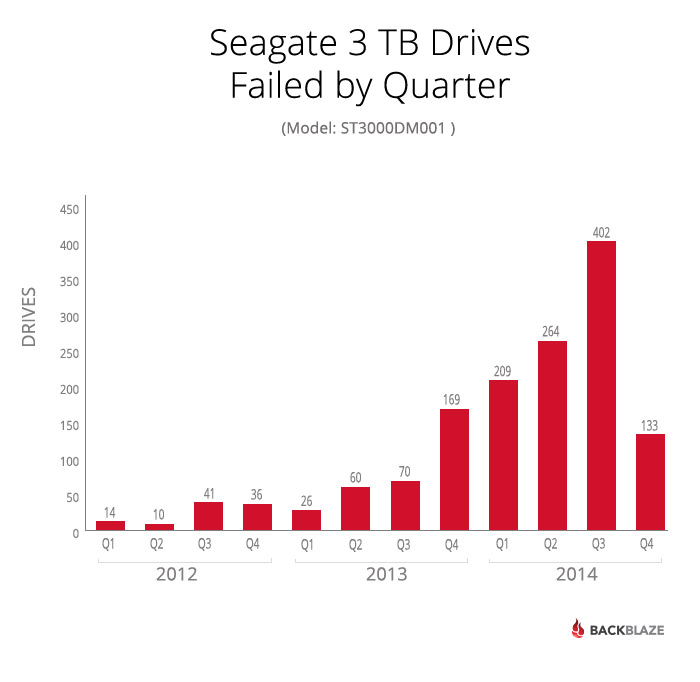
In annual terms, 2.7% or the drives failed in 2012, 5.4% failed in 2013, and 47.2% failed in 2014.
As of March 31, 2015, 1,423 of the 4,829 deployed Seagate 3TB drives had failed; that’s 29.5% of the drives.
Drive Failure Replacement and Testing
Let’s take a minute to describe what happens when a drive in a Storage Pod fails. When a drive fails, no data is compromised since we distribute data redundantly across multiple drives. Simply, the bad drive is replaced and the system is tested and rebuilt. During the entire process, the data is safe and available for file recovery as needed.
If during the rebuilding process, a second drives fails, the data is migrated to another Storage Pod where it is safe and available and the Storage Pod with the second failed drive is taken offline. Once offline, technicians go through a series of steps to assess the health of the system.
One of the health assessment steps can be to remove all the drives from the Storage Pod for testing. There are two different tests. The first test is similar to “advanced” reformatting and takes about 20 minutes. The second basically writes and reads all the sectors on the drive and takes several hours. Only if a drives passes both tests can it be reformatted and reused.
The Harbinger
The first sign of trouble was in May of 2013, when 27 drives failed. This was about 0.5% of the Seagate drives deployed at the time, a small number, but worth paying attention to. In June, there were 25 failures and in July there were 29, but it was in July 2013 that the failing drives issue came to the forefront.
During July and August 2013, three Storage Pods, all with Seagate drives, had drive failures. In all three cases, each time a drive was replaced and the rebuilding process restarted, additional drive failures would occur. At this point, all of the hard drives in each of the three Storage Pods were removed and scheduled for further testing. The Storage Pods themselves had new drives installed and went back into service.
The drives from the three Pods were removed and tested, as noted above, and about half of the drives from the three Storage Pods failed the first test. The remaining “good” drives were subjected to the second test and about 50% failed that test. The results were eye-opening. It was decided that all of the drives from the three Storage Pods would be removed from service and not redeployed.
Over the next several months, Seagate hard drives failed in noticeable quantities: 31 in October 2013, 68 in November, 70 in December and the upward trend continued in 2014. The only saving grace was that in nearly all cases, once a failed drive was replaced, the system would rebuild without incident. Any time a drive gave the least sign of trouble, it was removed and tested. Failing either of the external tests meant the drive was removed from service and placed with the “suspect” drives. The “suspect” pile was getting larger by the day.
Hitting the Wall
The failure count continued to rise and in the Spring of 2014 we had decided that if a Storage Pod with Seagate 3TB drives showed any type of drive failure we would 1) immediately migrate all the data and then 2) remove and test all the drives in the Storage Pod.
In July alone, 189 hard drives failed and another 273 were removed from service. The total, 462, was 11.4% of the Seagate 3TB drives operational on July 1st, 2014.
To be clear, a drive is marked “failed” because it failed in operation or during a rebuilding process. Drives marked “removed” are those that were removed from a Storage Pod that contained failed drives. When the “removed” drives were tested, nearly 75% of them failed one of the two tests done after removal. It could be argued that 25% of the “removed” drives were still good, even though they were assigned to the removed category, but these drives were never reinstalled.
Digging In
The Seagate 3TB drives purchased from November 2011 through December 2012 were failing at very high rates throughout 2014. If we look at the Seagate 3TB drives deployed during 2012, here is their status as of March 31, 2015.
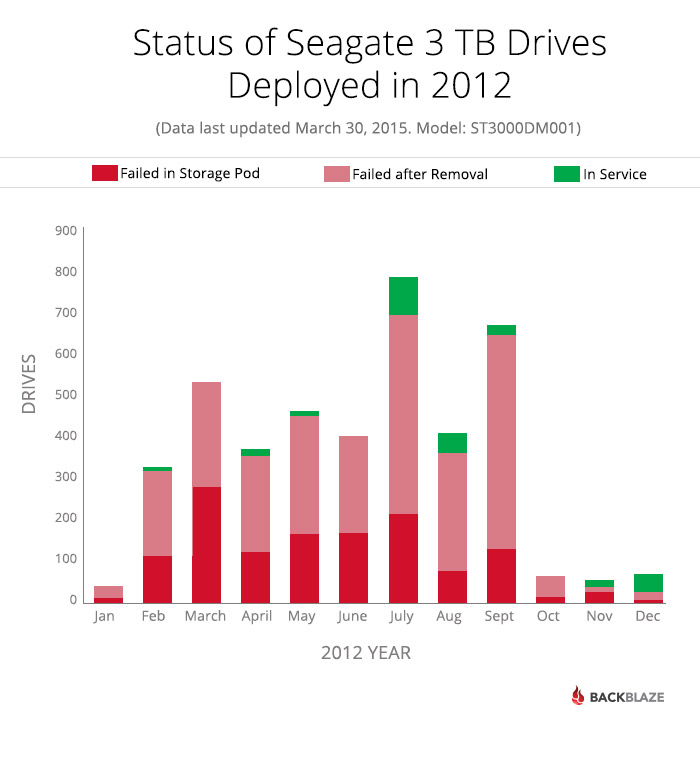
Only 251 of the 4,190 Seagate 3TB hard drives deployed in 2012 are still in service as of March 31, 2015. Breaking it down:
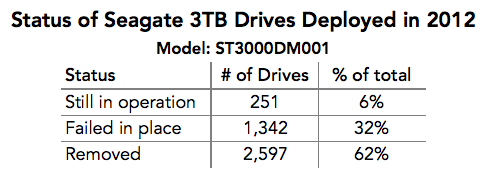
As a reminder, about 75% of the “removed” drives failed one of the bench tests once they were removed from a Storage Pod.
Thoughts and Theories
Theory: The Backblaze System
The first thing to consider is whether this was a systemic issue on our part. Let’s start with comparing the Seagate drives to other 3TB drives deployed in 2012.
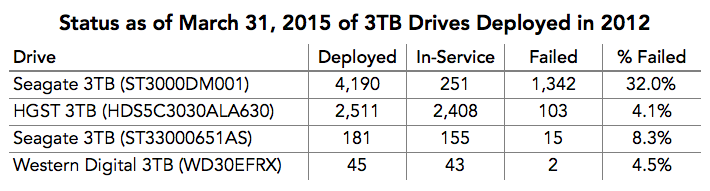
Given that the drives were deployed into the same environment, the Seagate 3TB drives didn’t fare as well.
Theory: Storage Pod 2.0
A second thing to consider is the model of the Storage Pod. In 2012, Version 2.0 was the only Storage Pod deployed; Version 3.0 was not used until February 2013. So all of the 3TB drives deployed in 2012 were installed in a Storage Pod 2.0 system. In the case of Seagate, the 3TB drives installed in 2012 performed reasonably well during the first and second years of operation; 2.7% of the drives in service failed in 2012 and a total of 7.7% of the drives deployed in 2012 had failed through the end of 2013. It was in 2014 that the drives seemed to “hit the wall.”
Conversely, as noted above, we also deployed 2,511 HGST drives, all into Version 2.0 Storage Pods. To date, they have not shown any signs of “hitting the wall,” with just 4.1% of the drives failing as of March 31, 2015.
Theory: Shucking External Drives
A third thing to consider was the use of “external” drives. Did the “shucking” of external drives inflate the number of drive failures? Consider the following chart.
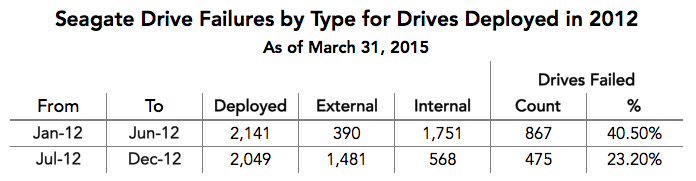
From January to June, most of the drives deployed were internal, but the percentage of drives that failed is higher during that period versus the July through December period where a majority of the drives deployed were external. In practice, the percentage of drives that failed is too high during either period regardless of whether or not the drive was shucked.
Adding to this is the fact that 300 of the Hitachi 3TB drives deployed in 2012 were external drives. These drives showed no evidence of failing at a higher rate than their internal counterparts.
Theory: The Drive Itself
This brings us to the final thing to consider, the drives themselves. The drives in question were produced beginning in Q3 of 2011. It was during this period that the Thailand Drive Crisis began. As a reminder, up to 50% of the world’s hard drive production was affected by the flooding in Thailand beginning in August 2011. The upheaval that occurred to the hard drive industry was well-documented. The drive manufacturers generally did not discuss how specific drive models were impacted by the flooding in Thailand, but perhaps the Seagate 3TB drives were impacted more than other models or other vendors. One thing is known—nearly every manufacturer reduced the warranty on their drives during the crisis with consumer drives like the Seagate model ST3000DM001 being reduced from three years to one year.
Conclusion
While this particular 3TB model had a painfully high rate of failure, subsequent Seagate models such as their 4TB drive, model: ST4000DM000, are performing well with an annualized 2014 failure rate of just 2.6% as of December 31, 2014. These drives come with three year warranties and show no signs of hitting the wall.
Backblaze currently has over 12,000 of these Seagate 4TB drives deployed and we have just purchased 5,000 more for use in our Backblaze Vaults.


