

Do you remember when “Pokémon Go” came out in 2016? Suddenly it was everywhere. It was a world-wide obsession, with over 10 million downloads in its first week and 500 million downloads in six months. System load rapidly escalated to 50 times the anticipated demand. How could the game architecture support such out-of-control hypergrowth?
The answer: At release time, Pokémon Go was “The largest Kubernetes deployment on Google Container Engine.” Kubernetes is a container orchestration tool that manages resources for dynamic web-scale applications, like “Pokémon Go.”
In this post, we’ll take a look at what Kubernetes does, how it works, and how it could be applicable in your environment.
What Is Kubernetes?
You may be familiar with containers. They’re conceptually similar to lightweight virtual machines. Instead of simulating computer hardware and running an entire operating system (OS) on that simulated computer, the container runs applications under a parent OS with almost no overhead. Containers allow developers and system administrators to develop, test, and deploy software and applications much faster than VMs, and most applications today are built with them.
But what happens if one of your containers goes down, or your ecommerce store experiences high demand, or if you release a viral sensation like “Pokémon Go”? You don’t want your application to crash, and you definitely don’t want your store to go down during the Christmas crush. Unfortunately, containers don’t solve those problems. You could implement intelligence in your application to scale as needed, but that would make your application a lot more complex and expensive to implement. It would be simpler and faster if you could use a drop-in layer of management—a “fleet manager” of sorts—to coordinate your swarm of containers. That’s Kubernetes.
Kubernetes Architecture: How Does Kubernetes Work?
Kubernetes implements a fairly straightforward hierarchy of components and concepts:
- Containers: Virtualized environments where the application code runs.
- Pods: “Logical hosts” that contain and manage containers, and potentially local storage.
- Nodes: The physical or virtual compute resources that run the container code.
- Cluster: A grouping of one or more nodes.
- Control Plane: Manages the worker nodes and Pods in the cluster.
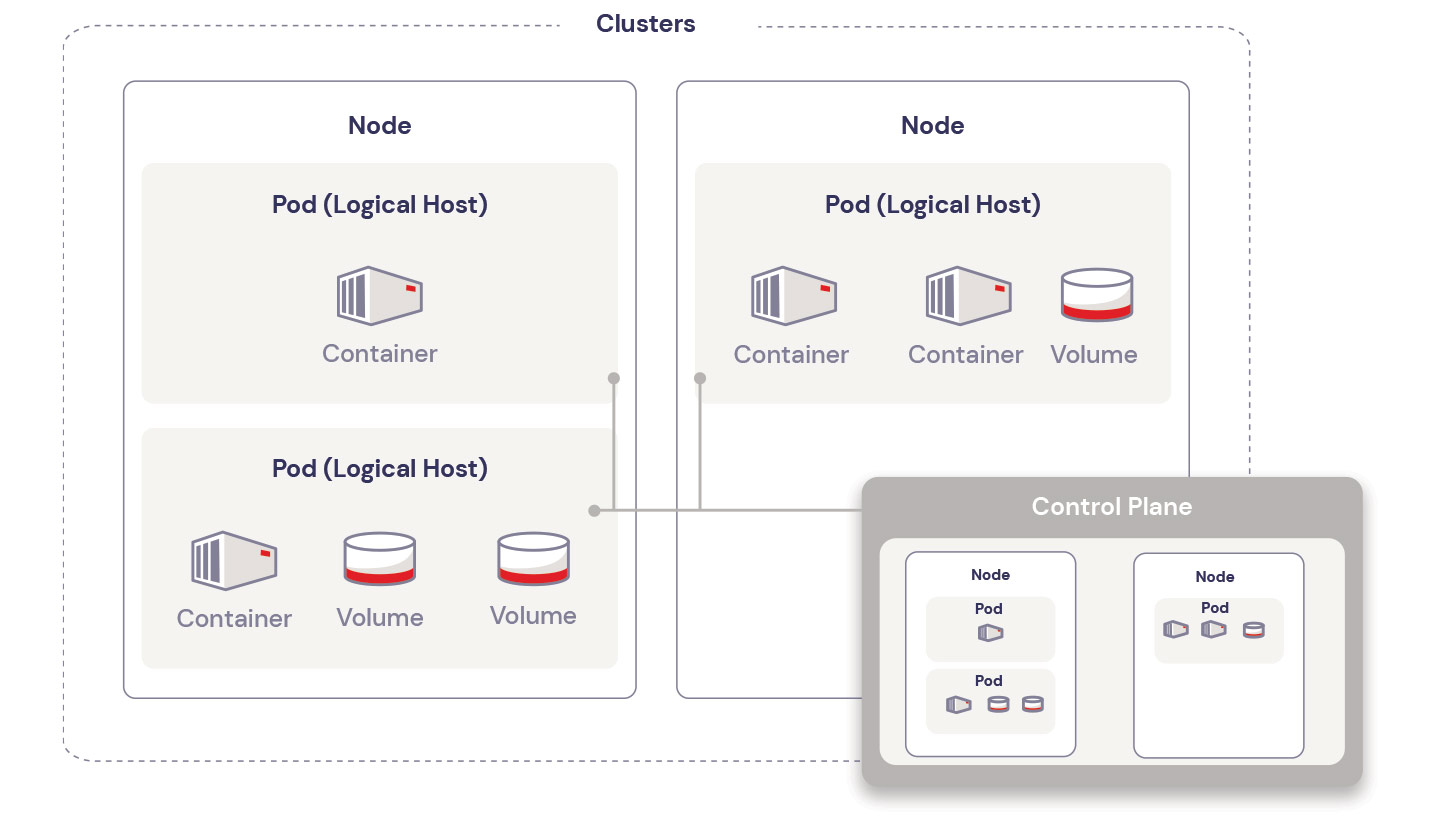
You have a few options to run Kubernetes. The minikube utility launches and runs a small single-node cluster locally for testing purposes. And you can control Kubernetes with any of several control interfaces: the kubectl command provides a command-line interface, and library APIs and REST endpoints provide programmable interfaces.
What Does Kubernetes Do?
Modern web-based applications are commonly implemented with “microservices,” each of which embodies one part of the desired application behavior. Kubernetes distributes the microservices across Pods. Pods can be used two ways—to run a single container (the most common use case) or to run multiple containers (like a pod of peas or a pod of whales—a more advanced use case). Kubernetes operates on the Pods, which act as a sort of wrapper around the container(s) rather than the containers themselves. As the microservices run, Kubernetes is responsible for managing the application’s execution. Kubernetes “orchestrates” the Pods, including:
- Autoscaling: As more users connect to the application’s website, Kubernetes can start up additional Pods to handle the load.
- Self-healing: If the code in a Pod crashes, or if there is a hardware failure, Kubernetes will detect it and restart the code in a new Pod.
- Parallel worker processes: Kubernetes distributes the Pods across multiple nodes to benefit from parallelism.
- Load balancing: If one server gets overloaded, Kubernetes can balance the load by migrating Pods to other nodes.
- Storage orchestration: Kubernetes lets you automatically mount persistent storage, say a local device or cloud-based object storage.
The beauty of this model is that the applications don’t have to know about the Kubernetes management. You don’t have to write load-balancing functionality into every application, or autoscaling, or other orchestration logic. The applications just run simplified microservices in a simple environment, and Kubernetes handles all the management complexity.
As an example: You write a small reusable application (say, a simple database) on a Debian Linux system. Then you could transfer that code to an Ubuntu system and run it, without any changes, in a Debian container. (Or, maybe you just download a database container from the Docker library.) Then you create a new application that calls the database application. When you wrote the original database on Debian, you might not have anticipated it would be used on an Ubuntu system. You might not have known that the database would be interacting with other application components. Fortunately, you didn’t have to anticipate the new usage paradigm. Kubernetes and containers isolate your code from the messy details.
Keep in mind, Kubernetes is not the only orchestration solution—there’s Docker Swarm, Hashicorp’s Nomad, and others. Cycle.io, for example, offers a simple container orchestration solution that focuses on ease for the most common container use cases.
Implementing Kubernetes: External Storage Required
Kubernetes spins up and spins down Pods as needed. Each Pod can host its own internal storage (as shown in the diagram above), but that’s not often used. A Pod might get discarded because the load has dropped, or the process crashed, or for other reasons. The Pods (and their enclosed containers and volumes) are ephemeral, meaning that their state is lost when they are destroyed. But most applications are stateful. They couldn’t function in a transitory environment like this. In order to work in a Kubernetes environment, the application must store its state information externally, outside the Pod. A new instance (a new Pod) must fetch the current state from the external storage when it starts up, and update the external storage as it executes.
You can specify the external storage when you create the Pod, essentially mounting the external volume in the container. The container running in the Pod accesses the external storage transparently, like any other local storage. Unlike local storage, though, cloud-based object storage is designed to scale almost infinitely right alongside your Kubernetes deployment. That’s what makes object storage an ideal match for applications running Kubernetes.
When you start up a Pod, you can specify the location of the external storage. Any container in the Pod can then access the external storage like any other mounted file system.
Kubernetes in Your Environment
While there’s no doubt a learning curve involved (Kubernetes has sometimes been described as “not for normal humans”), container orchestrators like Kubernetes, Cycle.io, and others can greatly simplify the management of your applications. If you use a microservice model, or if you work with similar cloud-based architectures, a container orchestrator can help you prepare for success from day one by setting your application up to scale seamlessly.


