

This year, we’re celebrating 10 years of Drive Stats—that’s 10 years of collecting the data and sharing the reports with all of you. While there’s some internal debate about who first suggested publishing the failure rates of drives, we all agree that Drive Stats has had impact well beyond our expectations. As of today, Drive Stats is still one of the only public datasets about drive usage, has been cited 150+ times by Google Scholar, and always sparks lively conversation, whether it’s at a conference, in the comments section, or in one of the quarterly Backblaze Engineering Week presentations.
This article is based on a presentation I gave during Backblaze’s internal Engineering Week, and is the result of a deep dive into managing and improving the architecture of our Drive Stats datasets. So, without further ado, let’s dive down the Drive Stats rabbit hole together.
More to Come
This article is part of a series on the nuts and bolts of Drive Stats. Up next, we’ll highlight some improvements we’ve made to the Drive Stats code, and we’ll link to them here. Stay tuned!
A “Simple” Ask
When I started at Backblaze in 2020, one of the first things I was asked to do was to “clean up Drive Stats.” It had not not been ignored per se, which is to say that things still worked, but it took forever and the teams that had worked on it previously were engaged in other projects. While we were confident that we had good data, running a report took about two and a half hours, plus lots of manual labor put in by Andy Klein to scrub and validate drives in the dataset.
On top of all that, the host on which we stored the data kept running out of space. But, each time we tried to migrate the data, something went wrong. When I started a fresh attempt at moving our dataset between hosts for this project, then ran the report, it ran for weeks (literally).
Trying to diagnose the root cause of the issue was challenging due to the amount of history surrounding the codebase. There was some code documentation, but not a ton of practical knowledge. In short, I had my work cut out for me.
Drive Stats Data Architecture
Let’s start with the origin of the data. The podstats generator runs on every Backblaze Storage Pod, what we call any host that holds customer data, every few minutes. It’s a legacy C++ program that collects SMART stats and a few other attributes, then converts them into an .xml file (“podstats”). Those are then pushed to a central host in each data center and bundled. Once the data leaves these central hosts, it has entered the domain of what we will call Drive Stats. This is a program that knows how to populate various types of data, within arbitrary time bounds based on the underlying podstats .xml files. When we run our daily reports, the lowest level of data are the raw podstats. When we run a “standard” report, it looks for the last 60 days or so of podstats. If you’re missing any part of the data, Drive Stats will download the necessary podstats .xml files.
Now let’s go into a little more detail: when you’re gathering stats about drives, you’re running a set of modules with dependencies to other modules, forming a data dependency tree. Each time a module “runs”, it takes information, modifies it, and writes it to a disk. As you run each module, the data will be transformed sequentially. And, once a quarter, we run a special module that collects all the attributes for our Drive Stats reports, collecting data all the way down the tree.
There’s a registry that catalogs each module, what their dependencies are, and their function signatures. Each module knows how its own data should be aggregated, such as per day, per day per cluster, global, data range, and so on. The “module type” will determine how the data is eventually stored on disk. Here’s a truncated diagram of the whole system, to give you an idea of what the logic looks like:
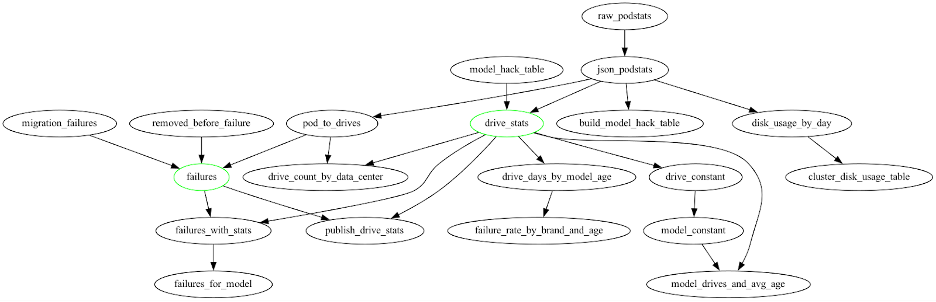
Let’s take model_hack_table as an example. This is a global module, and it’s a reference table that includes drives that might be exceptions in the data center. (So, any of the reasons Andy might identify in a report for why a drive isn’t included in our data, including testing out a new drive and so on.)
The green drive_stats module takes in the json_podstats file, references the model names of exceptions in model_hack_table, then cross references that information against all the drives that we have, and finally assigns them the serial number, brand name, and model number. At that point, it can do things like get the drive count by data center.
Similarly, pod_drives looks up the host file in our Ansible configuration to find out which Pods we have in which data centers. It then does attributions with a reference table so we know how many drives are in each data center.
As you move down through the module layers, the logic gets more and more specialized. When you run a module, the first thing the module does is check in with the previous module to make sure the data exists and is current. It caches the data to disk at every step, and fills out the logic tree step by step. So for example, drive_stats, being a “per-day” module, will write out a file such as /data/drive_stats/2023-01-01.json.gz when it finishes processing. This lets future modules read that file to avoid repeating work.
This work-deduplication process saves us a lot of time overall—but it also turned out to be the root cause of our weeks-long process when we were migrating Drive Stats to our new host.
Cache Invalidation Is Always Treacherous
We have to go into slightly more detail to understand what was happening. The dependency resolution process is as follows:
- Before any module can run, it checks for a dependency.
- For any dependency it finds, it checks modification times.
- The module has to be at least as old as the dependency, and the dependency has to be at least as old as the target data. If one of those conditions isn’t met, the data is recalculated.
- Any modules that get recalculated will trigger a rebuild of the whole branch of the logic tree.
When we moved the Drive Stats data and modules, I kept the modification time of the data (using rsync) because I knew in vague terms that Drive Stats used that for its caching. However, when Ansible copied the source code during the migration, it reset the modification time of the code for all source files. Since the freshly copied source files were younger than the dependencies, that meant the entire dataset was recalculating—and that represents terabytes of raw data dating back to 2013, which took weeks.
Note that Git doesn’t preserve mod times on source files, which is part of the reason this problem exists. Because the data doesn’t exist at all in Git, there’s no way to clone-while-preserving-date. Any time you do a code update or deploy, you run the risk of this same weeks-long process being triggered. However, this code has been stable for so long, tweaks to it wouldn’t invalidate the underlying base modules, and things more or less worked fine.
To add to the complication, lots of modules weren’t in their own source files. Instead, they were grouped together by function. A drive_days module might also be with a drive_days_by_model, drive_days_by_brand, drive_days_by_size, and so on, meaning that changing any of these modules would invalidate all of the other ones in the same file.
This may sound straightforward, but with all the logical dependencies in the various Drive Stats modules, you’re looking at pretty complex code. This was a poorly understood legacy system, so the invalidation logic was implemented somewhat differently for each module type, and in slightly different terms, making it a very unappealing problem to resolve.
Now to Solve
The good news is that, once identified, the solution was fairly intuitive. We decided to set an explicit version for each module, and save it to disk with the files containing its data. In Linux, there is something called an “extended attribute,” which is a small bit of space the filesystem preserves for metadata about the stored file—perfect for our uses. We now write a JSON object containing all of the dependent versions for each module. Here it is:
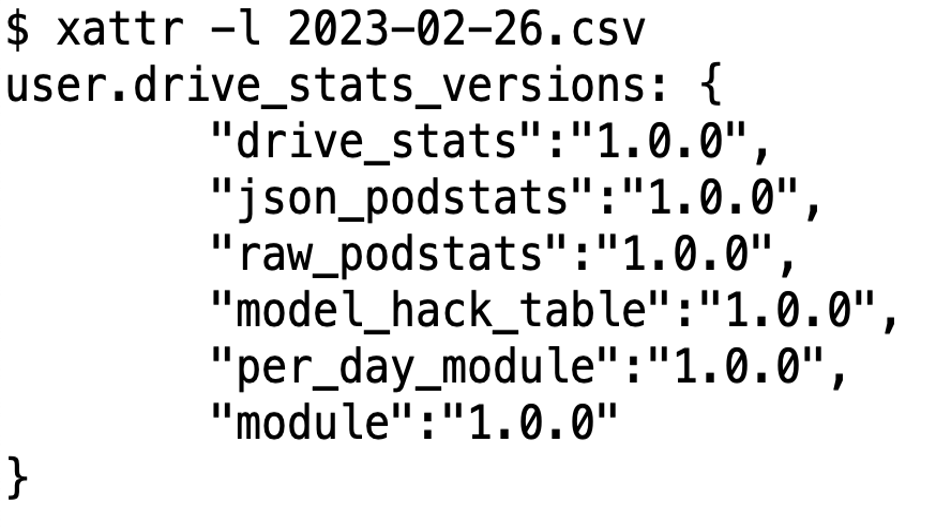
Now we will have two sets of versions, one stored on the files written to disk, and another set in the source code itself. So whenever a module is attempting to resolve whether or not it is out of date, it can check the versions on disk and see if they are compatible with the versions in source code. Additionally, since we are using semantic versioning, this means that we can do non-invalidating minor version bumps and still know exactly which code wrote a given file. Nice!
The one downside is that you have to manually specify to preserve extended attributes when using many Unix tools such as rsync (otherwise the version numbers don’t get copied). We chose the new default behavior in the presence of missing extended attributes to be for the module to print a warning and assume it’s current. We had a bunch of warnings the first time the system ran, but we haven’t seen them since. This way if we move the dataset and forget to preserve all the versions, we won’t invalidate the entire dataset by accident—awesome!
Wrapping It All Up
One of the coolest parts about this exploration was finding how many parts of this process still worked, and worked well. The C++ went untouched; the XML parser is still the best tool for the job; the logic of the modules and caching protocols weren’t fundamentally changed and had some excellent benefits for the system at large. We’re lucky at Backblaze that we’ve had many talented people work on our code over the years. Cheers to institutional knowledge.
That’s even more impressive when you think of how Drive Stats started—it was a somewhat off-the-cuff request. “Wouldn’t it be nice if we could monitor what these different drives are doing?” Of course, we knew it would have a positive impact on how we could monitor, use, and buy drives internally, but sharing that information is really what showed us how powerful this information could be for the industry and our community. These days we monitor more than 240,000 drives and have over 21.1 million days of data.
This journey isn’t over, by the way—stay tuned for parts two and three where we talk about improvements we made and some future plans we have for Drive Stats data. As always, feel free to sound off in the comments.


