

The AI and cloud infrastructure industry talks endlessly about GPUs, model size, and compute capacity, but there’s an invisible Achilles heel that can quietly undermine even the most promising AI projects: data egress.
According to a new Dimensional Research survey, 95% of organizations experience unexpected cloud storage fees, often from retrieval, egress, or API transactions. These hidden costs are rarely visible in early budgets, but they can torpedo innovation as workloads scale, especially when video enters the mix. Raw footage, frame-level training data, model checkpoints, and final renders can add up to hundreds of terabytes every week, straining both budgets and infrastructure.
Read the full report
We surveyed over 400 IT decision makers and one thing stood out. Surprise charges affect almost everyone. Learn what’s driving them—and how to avoid them.

Most generative AI video outputs today max out at 480p or 720p resolution. As demand grows for 1080p and 4K, storage and bandwidth requirements will multiply. Without a deliberate egress strategy, that growth becomes a silent tax on innovation. Over time, it restricts experimentation, reduces iteration speed, and undermines cost predictability.
The future of AI video belongs to teams that treat egress strategy as part of their innovation architecture and choose partners that let them move data freely between storage and compute, without penalty.
Inside the generative AI data pipeline
Modern AI systems no longer operate inside a single environment. Data is stored in one place, trained in another, and increasingly delivered at the edge. As workloads scale, the ability to move data efficiently becomes as important as compute capacity.
According to IDC, 88% of cloud buyers now deploy hybrid cloud environments, and 79% already use multiple providers. The Dimensional Research survey found that 99% of organizations struggle with limited flexibility and interoperability, highlighting how closed ecosystems are slowing progress just as multimodal AI demands more open, composable infrastructure.
To understand why egress matters so much for generative AI video, it helps to look at the AI data pipeline, which follows five continuous stages:
- Data ingest and active archive: Collect and store raw images, video, audio, and metadata for future processing.
- Data processing: Clean, label, and transform data into usable training sets.
- Model experimentation and training: Run GPU-intensive model development and fine-tuning, save checkpoints and weights.
- Model deployment and inference: Apply trained models to new video, user queries, or edge devices to generate results.
- Monitoring: Track accuracy, latency, and system health to retrain and optimize continuously.
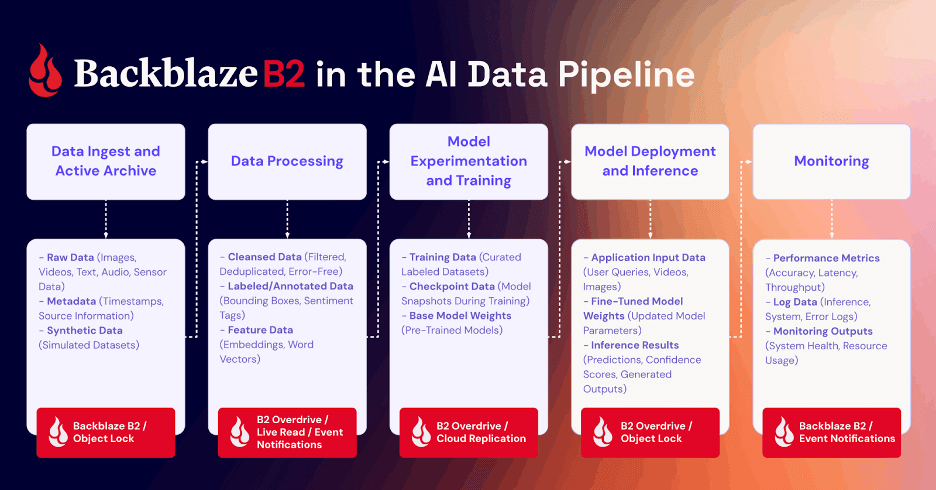
Each stage has distinct storage and compute requirements, but data moves between them constantly. For AI video, those transfers can span regions and providers. When egress is slow or expensive, the entire pipeline backs up, delaying iteration and driving up cost.
When data can’t move, innovation can’t either
Keeping everything under one cloud provider once simplified management. At first glance, it still seems convenient to keep storage, compute, and archive all in one place. Within a single AWS region, egress is free. But as soon as data crosses regions or providers, the model breaks down.
Tiered pricing makes costs hard to forecast. Egress fees penalize movement. Resource contention slows performance, and interoperability gaps lock teams into static configurations. AI video workloads amplify the problem: training, inference, and storage often require different environments optimized for each stage.
Dimensional Research’s data shows that 55% of organizations note egress costs as the single biggest barrier to switching cloud providers. Many stay with less efficient or more expensive infrastructure simply because the economics of mobility make innovation too costly. Moving just 1 PB of data out of AWS storage in the US East region costs about $53,800 per month—often enough to halt multi-cloud testing entirely.
The true cost, however, is in the experiments that are never run and the innovations that don’t get discovered because of a pricing structure that discourages exploration.
Freedom of data movement is the new competitive edge
In generative AI, the pace of progress is set by how quickly teams can test, retrain, and redeploy new models. That agility requires data mobility.
As organizations adopt composable AI stacks that mix specialized compute, regional storage, and orchestration tools, success depends on how openly data flows between them. Teams that design for movement can scale faster, adapt to new technologies, and stay resilient as infrastructure changes.
For teams building generative AI video applications, the impact is especially pronounced. A studio fine-tuning a diffusion model might burst to GPU providers with available capacity, render high-resolution outputs, and archive them for reuse, all without rewriting code or paying to move the data each time.
Data mobility has become a measure of competitiveness. The faster teams can move information across environments, the faster they can innovate.
How to build an egress strategy that fuels innovation
A good egress strategy ensures that storage and compute stay aligned as workloads scale. It helps teams anticipate cost, performance, and interoperability issues before they turn into blockers.
Here are a few practical steps to get there:
- Map your data flows. Identify where data originates, how it moves between services, and which transfers happen most frequently.
- Quantify transfer and API transaction costs. Include both in your total cost of ownership models. Even small fees add up quickly at petabyte scale.
- Test portability. Run controlled migrations or bursts to secondary compute providers to expose hidden bottlenecks.
- Select for openness. Favor vendors with flat, transparent pricing, free or low-cost egress, and broad S3 compatibility.
- Plan for growth. Multimodal models and higher-resolution video outputs will multiply data transfer volumes. Design bandwidth and budget models accordingly.
Beyond controlling costs, the goal is to keep flexibility built into your architecture so your team can use the best tools for each stage of the AI pipeline, without being trapped by pricing friction or closed ecosystems.
The Backblaze difference: Open by design
Storage that supports innovation shouldn’t penalize movement. That’s why we created Backblaze B2 Overdrive to give teams with high-throughput, data-intensive workloads the flexibility they need to innovate.
Overdrive is the right fit for AI video because of its:
- Predictable economics: $15/TB/month with unlimited free egress (no penalties for moving data to the compute you need).
- Zero transaction fees: API calls don’t become a hidden tax as pipelines scale.
- S3 compatibility and high throughput: Drop into existing pipelines without rewrites and keep large media workflows moving quickly across training, rendering, inference, and archive.
AI startup Decart put Backblaze B2 through its paces as it developed a real-time generative AI open world model, with millions of hours of training video data and multi-petabyte workloads daily.
What we really needed was a place where we could store an insane amount of data and, at the same time, download it to a few different GPU clusters around the world, and for all that to not cost an insane amount of money. That’s why we chose Backblaze.
—Dean Leitersdorf, Co-Founder and CEO, Decart
With Backblaze’s free egress model, they reduced AI operation costs by 75% while maintaining flexibility across compute environments.
If you’re scaling generative AI video, Backblaze B2 Overdrive gives you the freedom to put data where it performs best, without egress penalties, transaction surprises, or architectural do-overs.


