

In October of 2020, we announced that Facebook integrated Backblaze B2 Cloud Storage as a data transfer destination for their users’ photos and videos. This secure, encrypted service, based on code that Facebook developed with the open-source Data Transfer Project, allows users choices for how and where they manage or archive their media.
We spoke with Umar Mustafa, the Facebook partner engineer who led the project, about his team’s role in the Data Transfer Project (DTP) and the development process in configuring the data portability feature for Backblaze B2 Cloud Storage using open-source code. Read on to learn about the challenges of developing data portability including security and privacy practices, coding with APIs, and the technical design of the project.
Q: Can you tell us about the origin of Facebook’s data portability project?
A: Over a decade ago, Facebook launched a portability tool that allowed people to download their information. Since then, we have been adding functionality for people to have more control over their data.
In 2018, we joined the Data Transfer Project (DTP), which is an open-source effort by various companies, like Google, Microsoft, Twitter, and Apple, that aims to build products to allow people to easily transfer a copy of their data between services. The DTP tackles common problems like security, bandwidth limitations, and just the sheer inconvenience when it comes to moving large amounts of data.
And so in connection with this project, we launched a tool in 2019 that lets people port their photos and videos. Google was the first destination and we have partnered with more companies since then, with Backblaze being the most recent one.
Q: As you worked on this tool, did you have a sense for the type of Facebook customer that chooses to copy or transfer their photos and videos over to cloud storage?
A: Yes, we thought of various ways that people could use the tool. Someone might want to try out a new app that manages photos or they might want to archive all the photos and videos they’ve posted over the years in a private cloud storage service.
Q: Would you walk us through the choice to develop it using the open-source DTP code?
A: In order to transfer data between two services, you’d typically use the API from the first service to read data, then transform it if necessary for the second service, and finally use the API from the second service to upload it. While this approach works, you can imagine that it requires a lot of effort every time you need to add a new source or destination. And an API change by any one service would force all its collaborators to make updates.
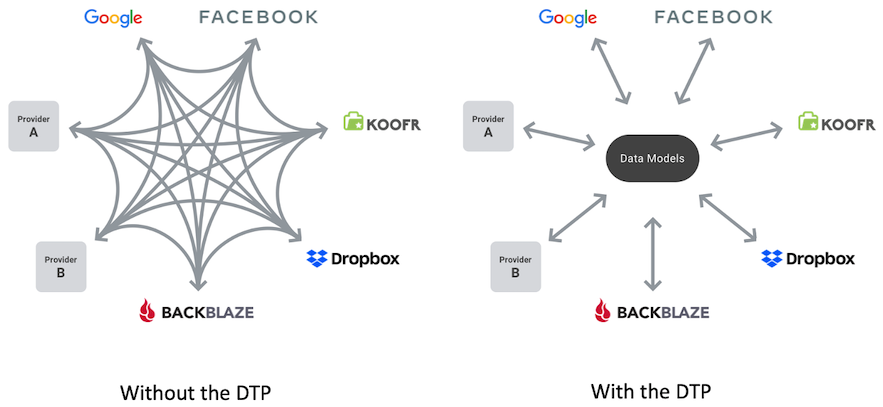
The DTP solves these problems by offering an open-source data portability platform. It consists of standard data models and a set of service adapters. Companies can create their import and export adapters, or for services with a public API, anyone can contribute the adapters to the project. As long as two services have adapters available for a specific data type (e.g. photos), that data can be transferred between them.
Being open-source also means anyone can try it out. It can be run locally using Docker, and can also be deployed easily in enterprise or cloud-based environments. At Facebook, we have a team that contributes to the project, and we encourage more people from the open-source community to join the effort. More details can be found about the project on GitHub.
Integrating a new service as a destination or a source for an existing data type normally requires adding two types of extensions, an auth extension and a transfer extension. The open-source code is well organized, so you can find all available auth extensions under the extensions/auth module and all transfer extensions under the extensions/data-transfer module, which you can refer to for guidance.
The auth extension only needs to be written once for a service and can be reused for each different data type that the service supports. Some common auth extensions, like OAuth, are already available in the project’s libraries folder and can be extended with very minimal code (mostly config). Alternatively, you can add your own auth extension as long as it implements the AuthServiceExtension interface.
A transfer extension consists of import adapters and export adapters for a service, and each of them is for a single data type. You’ll find them organized by service and data type in the extensions/data-transfer module. In order to add one, you’ll have to add a similar package structure, and write your adapter by implementing the Importer<a extends AuthData, T extends DataModel> interface using the respective AuthData and DataModel classes for the adapter.
For example, in Backblaze we created two import adapters, one for photos and one for videos. Each of them uses the TokenSecretAuthData containing the application key and secret. The photos importer uses the PhotosContainerResource as the DataModel and the videos importer uses the VideosContainerResource. Once you have the boilerplate code in place for the importer or exporter, you have to implement the required methods from the interface to get it working, using any relevant SDKs as you need. As Backblaze offers the Backblaze S3 Compatible API, we were able to use the AWS S3 SDK to implement the Backblaze adapters.
There’s a well written integration guide for the project on GitHub that you can follow for further details about integrating with a new service or data type.
Q: Why did you choose Backblaze as a storage endpoint?
A: We want people to be able to choose where they want to take their data. Backblaze B2 is a cloud storage of choice for many people and offers the Backblaze S3 Compatible API for easy integration. We’re happy to see people using Backblaze to save a copy of their photos and videos.
Q: Can you tell us about the comprehensive security and compliance review you conducted before locking in on Backblaze?
A: Privacy and security is of utmost importance for us at Facebook. When engaging with any partner, we check that they comply with certain standards. Some of the things that help us evaluate a partner include:
- Information security policies.
- Privacy policies.
- Third-party security certifications, as available.
We followed a similar approach to review the security and privacy practices that Backblaze follows, which are also demonstrated by various industry standard certifications.
Q: Describe the process of coding to Backblaze, anything you particularly enjoyed? Anything you found different or challenging? Anything surprising?
A: The integration for the data itself was easy to build. The Backblaze S3 Compatible API makes coding the adapters pretty straightforward, and Backblaze has good documentation around that.
The only difference between Backblaze and our other existing destinations was with authentication. Most adapters in the DTP use OAuth for authentication, where users log in to each service before initiating a transfer. Backblaze is different as it uses API keys-based authentication. This meant that we had to extend the UI in our tool to allow users to enter their application key details and wire that up as TokenSecretAuthData to the import adapters to transfer jobs securely.
Q: What interested you in data portability?
A: The concept of data portability sparked my interest once I began working at Facebook. Coincidentally, I had recently wondered if it would be possible to move my photos from one cloud backup service to another, and I was glad to discover a project at Facebook addressing the issue. More importantly, I felt that the problem it solves is important.
Facebook is always looking for new ways to innovate, so it comes with an opportunity to potentially influence how data portability will be commonly used and perceived in the future.
Q: What are the biggest challenges for DTP? It seems to be a pretty active project three years after launch. Given all the focus on it, what is it that keeps the challenge alive? What areas are particularly vexing for the project overall?
One major challenge we’ve faced is around technical design—currently the tool has to be deployed and run independently as a single instance to be able to make transfers. This has its advantages and disadvantages. On one hand, any entity or individual can run the project completely and enable transfers to any of the available services as long as the respective credentials are available. On the other hand, in order to integrate a new service, you need to redeploy all the instances where you need that service.
At the moment, Google has their own instance of the project deployed on their infrastructure, and at Facebook we have done the same, as well. This means that a well-working partnership model is required between services to offer the service to their respective users. As one of the maintainers of the project, we try to make this process as swift and hassle-free as possible for new partners.
With more companies investing time in data portability, we’ve started to see increased improvements over the past few months. I’m sure we’ll see more destinations and data types offered soon.


