

Over the past few months, we’ve explained how to store and query analytical data in Backblaze B2, and how to query the Drive Stats dataset using the Trino SQL query engine. Prompted by the recent expansion of Backblaze’s strategic partnership with Vultr, we took a closer look at how the Backblaze B2 + Vultr Cloud Compute combination performs for big data analytical workloads in comparison to similar services on Amazon Web Services (AWS).
Running an industry-standard benchmark, and because AWS is almost five times more expensive, we were expecting to see a trade-off between better performance on the single cloud AWS deployment and lower cost on the multi-cloud Backblaze/Vultr equivalent, but we were very pleasantly surprised by the results we saw.
Spoiler alert: not only was the Backblaze B2 + Vultr combination significantly more cost-effective than Amazon S3/EC2, it also outperformed the Amazon services by a wide margin. Read on for the details—we cover a lot of background on this experiment, but you can skip straight ahead to the results of our tests if you’d rather get to the good stuff.
First, Some History: The Evolution of Big Data Storage Architecture
Back in 2004, Google’s MapReduce paper lit a fire under the data processing industry, proposing a new “programming model and an associated implementation for processing and generating large datasets.” MapReduce was applicable to many real-world data processing tasks, and, as its name implies, presented a straightforward programming model comprising two functions (map and reduce), each operating on sets of key/value pairs. This model allowed programs to be automatically parallelized and executed on large clusters of commodity machines, making it well suited for tackling “big data” problems involving datasets ranging into the petabytes.
The Apache Hadoop project, founded in 2005, produced an open source implementation of MapReduce, as well as the Hadoop Distributed File System (HDFS), which handled data storage. A Hadoop cluster could comprise hundreds, or even thousands, of nodes, each one responsible for both storing data to disk and running MapReduce tasks. In today’s terms, we would say that each Hadoop node combined storage and compute.
With the advent of cloud computing, more flexible big data frameworks, such as Apache Spark, decoupled storage from compute. Now organizations could store petabyte-scale datasets in cloud object storage, rather than on-premises clusters, with applications running on cloud compute platforms. Fast intra-cloud network connections and the flexibility and elasticity of the cloud computing environment more than compensated for the fact that big data applications were now accessing data via the network, rather than local storage.
Today we are moving into the next phase of cloud computing. With specialist providers such as Backblaze and Vultr each focusing on a core capability, can we move storage and compute even further apart, into different data centers? Our hypothesis was that increased latency and decreased bandwidth would severely impact performance, perhaps by a factor of two or three, but cost savings might still make for an attractive alternative to colocating storage and compute at a hyperscaler such as AWS. The tools we chose to test this hypothesis were the Trino open source SQL Query Engine and the TPC-DS benchmark.
Benchmarking Deployment Options With TPC-DS
The TPC-DS benchmark is widely used to measure the performance of systems operating on online analytical processing (OLAP) workloads, so it’s well suited for comparing deployment options for big data analytics.
A formal TPC-DS benchmark result measures query response time in single-user mode, query throughput in multiuser mode and data maintenance performance, giving a price/performance metric that can be used to compare systems from different vendors. Since we were focused on query performance rather than data loading, we simply measured the time taken for each configuration to execute TPC-DS’s set of 99 queries.
Helpfully, Trino includes a tpcds catalog with a range of schemas each containing the tables and data to run the benchmark at a given scale. After some experimentation, we chose scale factor 10, corresponding to approximately 10GB of raw test data, as it was a good fit for our test hardware configuration. Although this test dataset was relatively small, the TPC-DS query set simulates a real-world analytical workload of complex queries, and took several minutes to complete on the test systems. It would be straightforward, though expensive and time consuming, to repeat the test for larger scale factors.
We generated raw test data from the Trino tpcds catalog with its sf10 (scale factor 10) schema, resulting in 3GB of compressed Parquet files. We then used Greg Rahn’s version of the TPC-DS benchmark tools, tpcds-kit, to generate a standard TPC-DS 99-query script, modifying the script syntax slightly to match Trino’s SQL dialect and data types. We ran the set of 99 queries in single user mode three times on each of three combinations of compute/storage platforms: EC2/S3, EC2/B2 and Vultr/B2. The EC2/B2 combination allowed us to isolate the effect of moving storage duties to Backblaze B2 while keeping compute on Amazon EC2.
A note on data transfer costs: AWS does not charge for data transferred between an Amazon S3 bucket and an Amazon EC2 instance in the same region. In contrast, the Backblaze + Vultr partnership allows customers free data transfer between Backblaze B2 and Vultr Cloud Compute across any combination of regions.
Deployment Options for Cloud Compute and Storage
AWS
The EC2 configuration guide for Starburst Enterprise, the commercial version of Trino, recommends a r4.4xlarge EC2 instance, a memory-optimized instance offering 16 virtual CPUs and 122 GiB RAM, running Amazon Linux 2.
Following this lead, we configured an r4.4xlarge instance with 32GB of gp2 SSD local disk storage in the us-west-1 (Northern California) region. The combined hourly cost for the EC2 instance and SSD storage was $1.19.
We created an S3 bucket in the same us-west-1 region. After careful examination of the Amazon S3 Pricing Guide, we determined that the storage cost for the data on S3 was $0.026 per GB per month.
Vultr
We selected Vultr’s closest equivalent to the EC2 r4.4xlarge instance: a Memory Optimized Cloud Compute instance with 16 vCPUs, 128GB RAM plus 800GB of NVMe local storage, running Debian 11, at a cost of $0.95/hour in Vultr’s Silicon Valley region. Note the slight difference in the amount of available RAM–Vultr’s virtual machine (VM) includes an extra 6GB, despite its lower cost.
Backblaze B2
We created a Backblaze B2 Bucket located in the Sacramento, California data center of our U.S. West region, priced at $0.005/GB/month, about one-fifth the cost of Amazon S3.
Trino Configuration
We used the official Trino Docker image configured identically on the two compute platforms. Although a production Trino deployment would typically span several nodes, for simplicity, time savings, and cost-efficiency we brought up a single-node test deployment. We dedicated 78% of the VM’s RAM to Trino, and configured its Hive connector to access the Parquet files via the S3 compatible API. We followed the Trino/Backblaze B2 getting started tutorial to ensure consistency between the environments.
Benchmark Results
The table shows the time taken to complete the TPC-DS benchmark’s 99 queries. We calculated the mean of three runs for each combination of compute and storage. All times are in minutes and seconds, and a lower time is better.
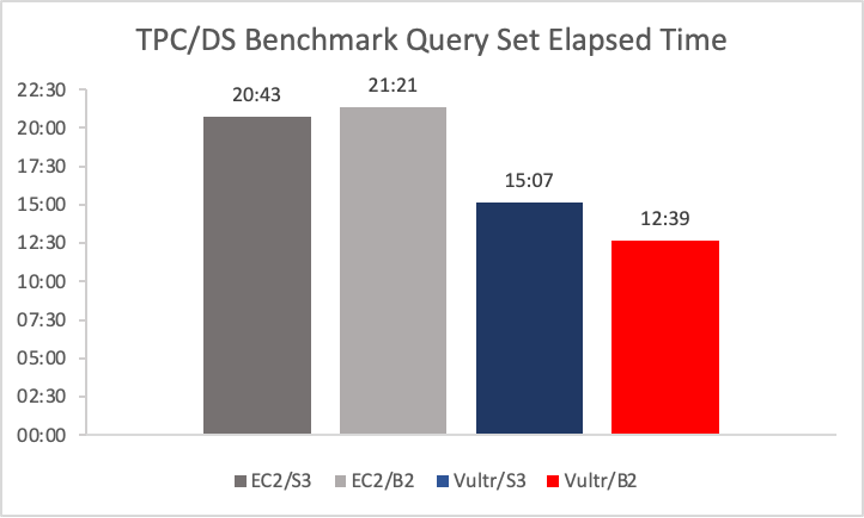
We used Trino on Amazon EC2 accessing data on Amazon S3 as our starting point; this configuration ran the benchmark in 20:43.
Next, we kept Trino on Amazon EC2 and moved the data to Backblaze B2. We saw a surprisingly small difference in performance, considering that the data was no longer located in the same AWS region as the application. The EC2/B2 Storage Cloud combination ran the benchmark just 38 seconds slower (that’s about 3%), clocking in at 21:21.
When we looked at Trino running on Vultr accessing data on Amazon S3, we saw a significant increase in performance. On Vultr/S3, the benchmark ran in 15:07, 27% faster than the EC2/S3 combination. We suspect that this is due to Vultr providing faster vCPUs, more available memory, faster networking, or a combination of the three. Determining the exact reason for the performance delta would be an interesting investigation, but was out of scope for this exercise.
Finally, looking at Trino on Vultr accessing data on Backblaze B2, we were astonished to see that not only did this combination post the fastest benchmark time of all, Trino on Vultr/Backblaze B2’s time of 12:39 was 16% faster than Vultr/S3 and 39% faster than Trino on EC2/S3!
Note: this is not a formal TPC-DS result, and the query times generated cannot be compared outside this benchmarking exercise.
The Bottom Line: Higher Performance at Lower Cost
For the scale factor 10 TPC-DS data set and queries, with comparably specified instances, Trino running on Vultr retrieving data from Backblaze B2 is 39% faster than Trino on EC2 pulling data from S3, with 20% lower compute cost and 76% lower storage cost.
You can get started with both Backblaze B2 and Vultr free of charge—click here to sign up for Backblaze B2, with 10GB free storage forever, and click here for $250 of free credit at Vultr.


