
What do Sherlock Holmes and ChatGPT have in common? Inference, my dear Watson!
“We approached the case, you remember, with an absolutely blank mind, which is always an advantage. We had formed no theories. We were simply there to observe and to draw inferences from our observations.”
—Sir Arthur Conan Doyle, The Adventures of the Cardboard Box
As we all continue to refine our thinking around artificial intelligence (AI), it’s useful to define terminology that describes the various stages of building and using AI algorithms—namely, the AI training stage and the AI inference stage. As we see in the quote above, these are not new concepts: they’re based on ideas and methodologies that have been around since before Sherlock Holmes’ time.
If you’re using AI, building AI, or just curious about AI, it’s important to understand the difference between these two stages so you understand how data moves through an AI workflow. That’s what I’ll explain today.
The TL:DR
The difference between these two terms can be summed up fairly simply: first you train an AI algorithm, then your algorithm uses that training to make inferences from data. To create a whimsical analogy, when an algorithm is training, you can think of it like Watson—still learning how to observe and draw conclusions through inference. Once it’s trained, it’s an inferring machine, a.k.a. Sherlock Holmes.
Whimsy aside, let’s dig a little deeper into the tech behind AI training and AI inference, the differences between them, and why the distinction is important.
Obligatory Neural Network Recap
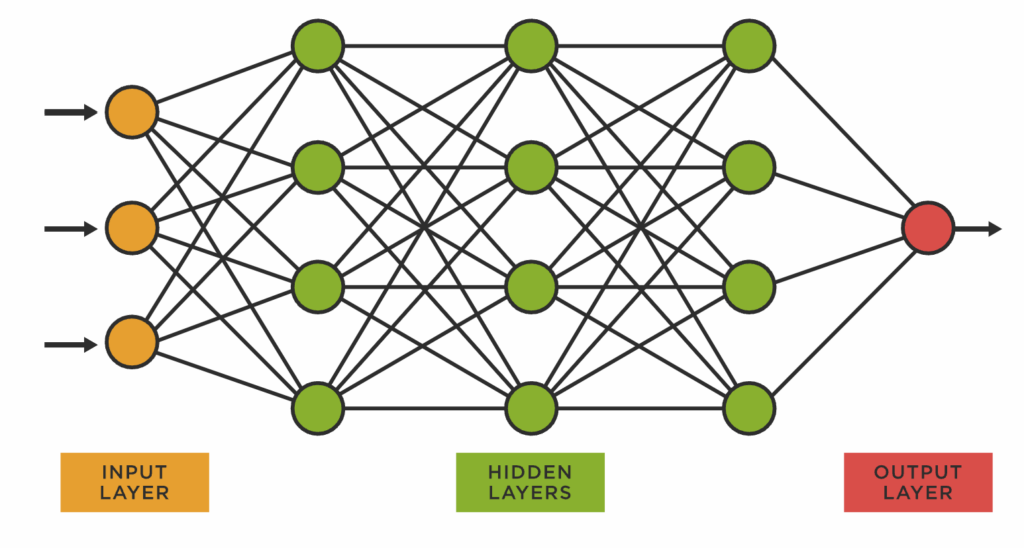
Neural networks have emerged as the brainpower behind AI, and a basic understanding of how they work is foundational when it comes to understanding AI.
Complex decisions, in theory, can be broken down into a series of yeses and nos, which means that they can be encoded in binary. Neural networks have the ability to combine enough of those smaller decisions, weigh how they affect each other, and then use that information to solve complex problems. And, because more complex decisions require more points of information to come to a final decision, they require more processing power. Neural networks are one of the most widely used approaches to AI and machine learning (ML).
What Is AI Training?: Understanding Hyperparameters and Parameters
In simple terms, training an AI algorithm is the process through which you take a base algorithm and then teach it how to make the correct decision. This process requires large amounts of data, and can include various degrees of human oversight. How much data you need has a relationship to the number of parameters you set for your algorithm as well as the complexity of a problem.
We made this handy dandy diagram to show you how data moves through the training process:
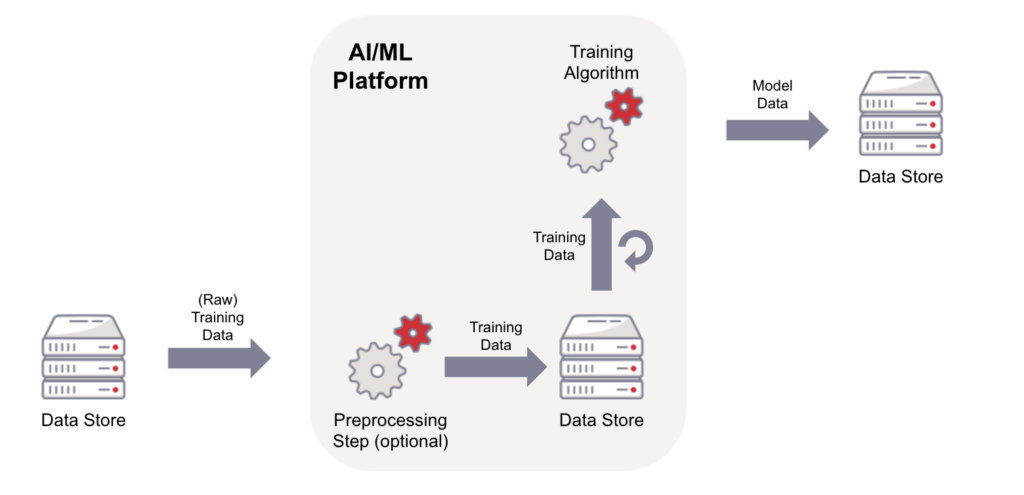
And hey—we’re leaving out a lot of nuance in that conversation because dataset size, parameter choice, etc. is a graduate-level topic on its own, and usually is considered proprietary information by the companies who are training an AI algorithm. It suffices to say that dataset size and number of parameters are both significant and have a relationship to each other, though it’s not a direct cause/effect relationship. And, both the number of parameters and the size of the dataset affect things like processing resources—but that conversation is outside of scope for this article (not to mention a hot topic in research).
As with everything, your use case determines your execution. Some types of tasks actually see excellent results with smaller datasets and more parameters, whereas others require more data and fewer parameters. Bringing it back to the real world, here’s a very cool graph showing how many parameters different AI systems have. Note that they very helpfully identified what type of task each system is designed to solve:
So, let’s talk about what parameters are with an example. Back in our very first AI 101 post, we talked about ways to frame an algorithm in simple terms:
Machine learning does not specify how much knowledge the bot you’re training starts with—any task can have more or fewer instructions. You could ask your friend to order dinner, or you could ask your friend to order you pasta from your favorite Italian place to be delivered at 7:30 p.m.
Both of those tasks you just asked your friend to complete are algorithms. The first algorithm requires your friend to make more decisions to execute the task at hand to your satisfaction, and they’ll do that by relying on their past experience of ordering dinner with you—remembering your preferences about restaurants, dishes, cost, and so on.
The factors that help your friend make a decision about dinner are called hyperparameters and parameters. Hyperparameters are those that frame the algorithm—they are set outside the training process, but can influence the training of the algorithms. In the example above, a hyperparameter would be how you structure your dinner feedback. Do you thumbs up or down each dish? Do you write a short review? You get the idea.
Parameters are factors that the algorithm derives through training. In the example above, that’s what time you prefer to eat dinner, which restaurants you enjoy after eating, and so on.
When you’ve trained a neural network, there will be heavier weights between various nodes. That’s a shorthand of saying that an algorithm will prefer a path it knows is significant, and if you want to really get nerdy with it, this article is well-researched, has a ton of math explainers for various training methods, and includes some fantastic visuals. For our purposes, here’s one way people visualize a “trained” algorithm:
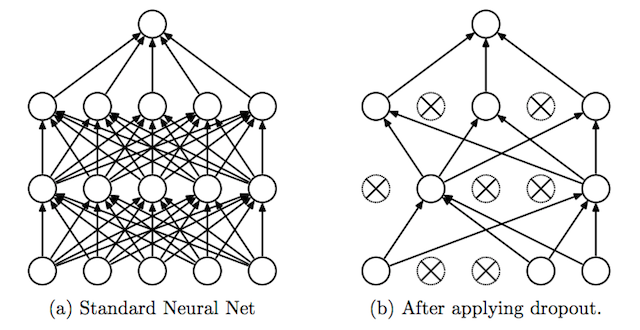
The “dropout method” is essentially adding weight to the relationships an AI algorithm has found to be significant for the dataset it’s working on. It can then de-prioritize (or sometimes even eliminate) the other relationships.
Once you have a trained algorithm, then you can use it with a reasonable degree of certainty that it will give you good results, and that leads us to inference.
What Is AI Inference?
Once you’ve trained your algorithm, you can send it out in the world to do its job (and make yours easier). When you present a trained AI algorithm with a problem and it gives you an answer, that’s called inference. It’s using the way it was trained to draw conclusions or make predictions, depending on how it was built, and once an algorithm is in the “inference stage”, it’s no longer learning (usually).
Here’s our diagram for how data might move through an inference process:
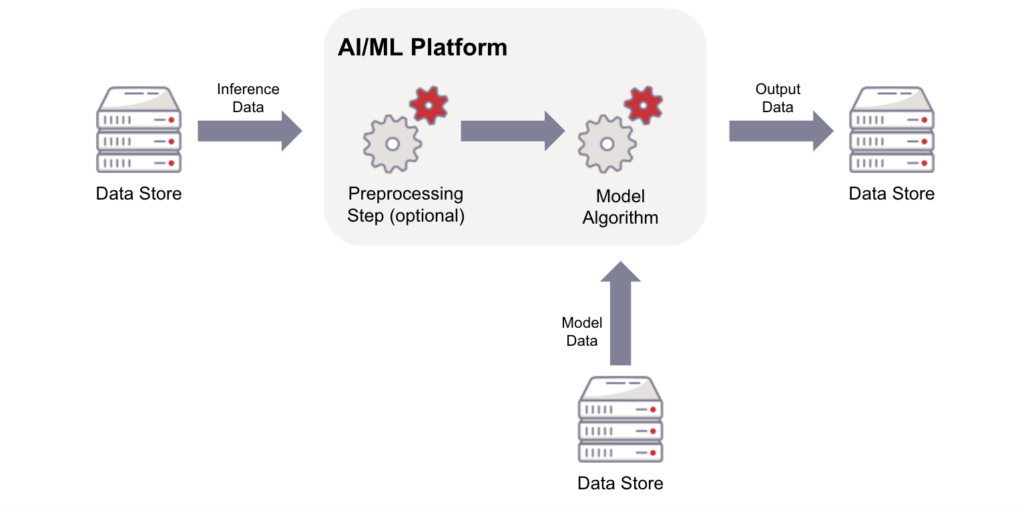
As we’ve seen in the real world, this does not mean that the AI model will give you a perfect answer every time—depending on, for example, the AI’s access to new or current information, the complexity of training, etc., the algorithm might give you a better or worse (more or less accurate) answer. But, it will be able to look at a new piece of information or dataset, and return a response.
When I asked our friend ChatGPT about this, it broke down inference and defined it in relation to the logical underpinnings of different types of algorithms. (As a mere human, how could I resist using inference while writing about inference?) Sure, ChatGPT may be merely mimicking human-like dialogue based on its ingestion of the whole internet, then giving me the most likely answer based on its specialized neural network that predicts the likelihood of the next word in response to my conversational query and without access to data after January 2022, but here’s what our AI friend had to say for itself:
- Machine Learning Inference: In machine learning, after a model has been trained on a dataset, it is deployed to make predictions or classifications on new, unseen data. During inference, the model takes the input data, processes it, and produces an output or a prediction based on the patterns and relationships it learned during training. For example, a trained machine learning model might be used to classify images, predict stock prices, or identify spam emails.
- Deep Learning Inference: Deep learning, a subfield of machine learning, involves neural networks with multiple layers. In deep learning, inference means feeding an input through a trained deep neural network and obtaining an output. This is commonly used in applications like image recognition, natural language processing, and speech recognition. Inference in deep learning can be computationally intensive, and specialized hardware, such as GPUs and TPUs, are often used to accelerate the process.
- Rule-Based Systems Inference: In rule-based AI systems, inference is the process of applying logical rules to make decisions or draw conclusions. These systems use a set of predefined rules and facts to reason and infer new information. For example, in an expert system for medical diagnosis, inference involves applying a set of rules to patient symptoms and medical knowledge to arrive at a diagnosis.
- Probabilistic Inference: In probabilistic AI, inference is used to estimate probabilities and uncertainty. Bayesian networks and Markov decision processes are examples of probabilistic models that perform inference to compute probabilities of events or make decisions based on probabilities.
You’ll notice that each of these are saying basically the same thing: the AI algorithm applies its decision-making paradigm to a problem.
Why Stop Learning During the Inference Stage?
In general, it’s important to keep these two stages—training and inference—of an AI algorithm separate for a few reasons:
- Efficiency: Training is typically a computationally intensive process, whereas inference is usually faster and less resource-intensive. Separating them allows for efficient use of computational resources.
- Generalization: The model’s ability to generalize from training data to unseen data is a key feature. It should not learn from every new piece of data it encounters during inference to maintain this generalization ability.
- Reproducibility: When using trained models in production or applications, it’s important to have consistency and reproducibility in the results. If models were allowed to learn during inference, it would introduce variability and unpredictability in their behavior.
There are some specialized AI algorithms that want to continue learning during the inference stage—your Netflix algorithm is a good example, as are self-driving cars, or dynamic pricing models used to set airfare pricing. On the other hand, the majority of problems we’re trying to solve with AI algorithms deliver better decisions by separating these two phases—think of things like image recognition, language translation, or medical diagnosis, for example.
Training vs. Inference (But, Really: Training Then Inference)
To recap: the AI training stage is when you feed data into your learning algorithm to produce a model, and the AI inference stage is when your algorithm uses that training to make inferences from data. Here’s a chart for quick reference:
| Table | Inference |
|---|---|
| Feed training data into a learning algorithm | Apply the model to the inference data |
| Produces a model comprising code and data | Produces output data |
| One time-ish (Requirement to retain training data in case of re-training.) | Often continuous |
The difference may seem inconsequential at first glance, but defining these two stages helps to show implications for AI adoption particularly with businesses. That is, given that it’s much less resource intensive (and therefore, less expensive), it’s likely to be much easier for businesses to integrate already-trained AI algorithms with their existing systems.
And, as always, we’re big believers in demystifying terminology for discussion purposes. Let us know what you think in the comments, and feel free to let us know what you’re interested in learning about next.


