

Disaster recovery (DR) is a top-line priority for enterprise organizations facing increasingly complex threats—sophisticated ransomware attacks, widespread cloud outages, and regulatory risks. The ability to recover quickly and maintain business continuity isn’t just a technical necessity—it’s a competitive imperative.
Today, I’m breaking down foundational strategies for enterprise DR readiness. You’ll find practical guidance on infrastructure design, site strategy, backup best practices, and more to help you take immediate action.
Get the full guide
Our “Essential Guide to Disaster Recovery Planning” offers a comprehensive framework for designing a DR plan that protects your business across multiple threat vectors.

Choose the right infrastructure: Beyond legacy limitations
Many enterprises still rely on legacy storage technologies like tape, which create delays in restoration and introduce hardware failure risks. Shifting to cloud-first infrastructure reduces these vulnerabilities while unlocking scalability and location diversity. It also supports immutability features—critical for ransomware resilience—and simplifies compliance with evolving regulations.
Cloud platforms also unlock new options for data governance and sovereignty. Enterprises operating across regions or industries governed by strict data residency laws can configure cloud storage to maintain compliance while reducing operational overhead.
As enterprise backup and archive needs grow, it becomes vital to distinguish between long-term cold storage and actively accessible data. With clear infrastructure planning, organizations can streamline operations and ensure faster recovery without overspending on high-performance systems for archival workloads.
What is Object Lock?
Object Lock is the feature in cloud platforms that enables immutability. With immutability, your data cannot be changed, deleted, or encrypted. This is the ultimate protection against ransomware.DR site temperatures: Hot, warm, or cold?
Depending on your recovery time objective (RTO), different types of recovery sites offer different benefits:
- Hot sites: Fully mirrored and ready for instant failover—great for mission-critical apps but expensive.
- Warm sites: Pre-configured but not fully live—strike a balance between cost and speed.
- Cold sites: Infrastructure is ready but requires manual configuration—most affordable, but slowest to recover.
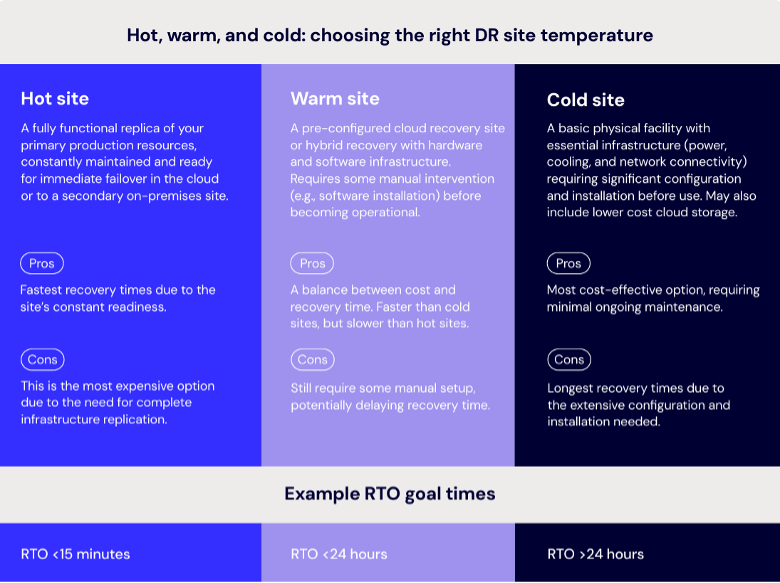
Enterprises evaluating DR readiness should consider whether their current configuration meets their recovery time goals—and whether they’re optimizing for the right workloads. Comparing hot, warm, and cold site models can help strike the right balance between performance and budget.
Build vs. buy vs. cloud: Finding the right fit
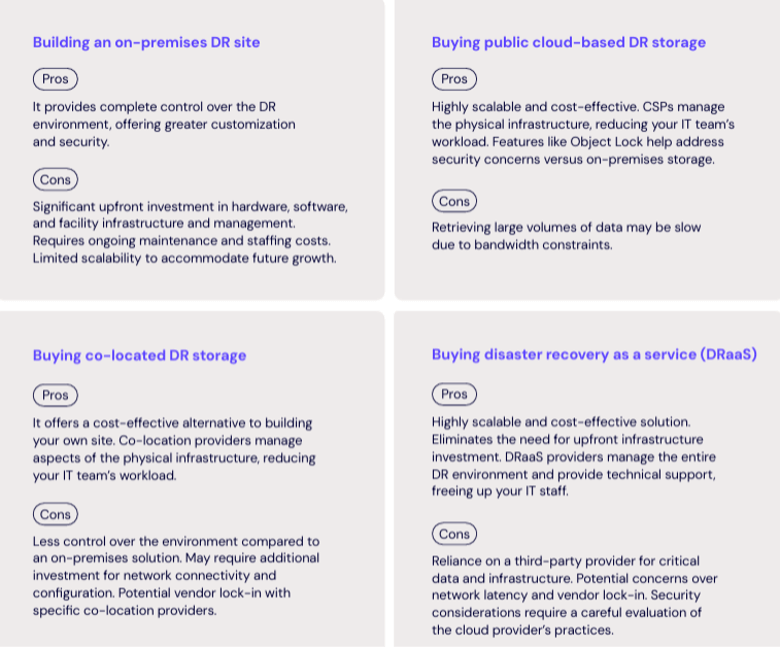
Selecting a DR site is fundamental to your strategy. There are four main approaches to establishing a DR site: building your own, buying services from a co-location provider, buying public cloud storage, or leveraging a disaster recovery as a service (DRaaS) solution. Each approach offers distinct advantages and drawbacks.
Building an on-premises DR site
Pros: It provides complete control over the DR environment, offering greater customization and security.
Cons: Significant upfront investment in hardware, software, and facility infrastructure and management. Requires ongoing maintenance and staffing costs. Limited scalability to accommodate future growth.
Buying co-located DR storage
Pros: It offers a cost-effective alternative to building your own site. Co-location providers manage aspects of the physical infrastructure, reducing your IT team’s workload.
Cons: Less control over the environment compared to an on-premises solution. May require additional investment for network connectivity and configuration. Potential vendor lock-in with specific co-location providers.
Buying public cloud-based DR storage
Pros: Highly scalable and cost-effective. CSPs manage the physical infrastructure, reducing your IT team’s workload. Features like Object Lock help address security concerns versus on-premises storage.
Cons: Retrieving large volumes of data may be slow due to bandwidth constraints.
Buying disaster recovery as a service (DRaaS)
Pros: Highly scalable and cost-effective solution. Eliminates the need for upfront infrastructure investment. DRaaS providers manage the entire DR environment and provide technical support, freeing up your IT staff.
Cons: Reliance on a third-party provider for critical data and infrastructure. Potential concerns over network latency and vendor lock-in. Security considerations require a careful evaluation of the cloud provider’s practices.
Backup vs. replication: Know the difference
Replication copies data in real-time, but that also means it can copy infected or corrupted data. Backups, on the other hand, offer point-in-time recoveries so you can restore data even after a ransomware attack.
This distinction between backups and replication is critical: If you only rely on replication, you could end up replicating the attack itself.
The optimal approach to DR depends on your specific needs.
- For frequently accessed data requiring near-instantaneous recovery, consider a combination of hot site methodology and real-time data replication. This offers the fastest failover, but can come at a higher cost.
- For critical data with acceptable downtime, a warm site with replicated immutable backups at a secondary location (either on-premises or in the cloud) provides a good balance between cost and recovery time. While requiring some manual intervention, it offers protection against malware replicating to the DR site.
- For less critical data or archival purposes, cold storage with periodic backups is a cost-effective option. Backups offer a historical record and are less susceptible to malware infection compared to replicated data, particularly if Object Lock is enabled for immutability.
SaaS outages are a threat you can’t ignore
Although built for high availability, SaaS apps don’t guarantee protection against data loss. Tools like Microsoft 365 and Google Workspace are built for uptime, not recovery. Misconfigurations, insider threats, and accidental deletions remain common risks. Enterprises should take control of their own retention policies with dedicated SaaS backup strategies, including regular point-in-time snapshots and recovery testing.
Additionally, planning for SaaS outages should include identifying local alternatives for core business functions. Can teams temporarily revert to offline workflows? Are key contacts available outside of email or Slack? Defining fallback protocols ensures that productivity doesn’t grind to a halt even if your primary tools go dark.
Assembling your incident response team
The incident response team (IRT) is the backbone of your DR response and is responsible for leading the recovery efforts during a disaster. Here’s a breakdown of possible key IRT roles:
- Incident commander: Oversees the entire incident response process, making critical decisions and delegating tasks to team members.
- Technical lead: Provides technical expertise, directing recovery efforts for IT infrastructure and data restoration.
- Communications lead: Handles external and internal communication, ensuring timely updates for stakeholders and mitigating potential reputational damage.
- Documentation lead: Maintains the DR runbook, ensuring its accuracy and updating it with post-incident findings.
- Legal counsel: Provides legal guidance and ensures compliance with relevant regulations during the response and recovery process.
Objectives, priorities, and KPIs: The compass of your DR strategy
A robust DR strategy starts with clearly defined objectives and priorities. These guide your approach and decision-making during a disaster recovery event. Your strategy should prioritize rapid recovery of critical systems and applications to minimize operational downtime and resume normal functions swiftly.
Prioritization: Not all data (or systems) are created equal
Prioritizing your critical business applications depends on a deep understanding of your business. Collaborate with internal partners to identify critical business applications that are essential for ongoing operations. Not all applications require immediate restoration. Prioritize systems based on their impact on core business functions.
Documentation is key
A popular mantra for DR specialists is “Test the plan; don’t plan the test.” Your DR plans must be clearly documented as working recipes for application and data recovery, including dependencies and prerequisites. Document the recovery procedures for each critical application, outlining the steps required to bring them back online. This ensures your IT team can efficiently restore essential services during a disaster.
Primary DR objectives
- Minimize data loss: The primary objective is to minimize data loss through regular backups and secure storage practices.
- Ensure business continuity: The DR plan aims to rapidly recover operation of critical functions during a disaster, minimizing disruption to the business goals.
- Optimize costs: Application and data recovery needs to balance speed and costs to ensure recoverability without unnecessarily increasing IT spending.
Compliance considerations
Compliance regulations might influence your DR priorities. Understand any industry-specific regulations or data privacy laws that might dictate specific data protection and recovery timeframes.
Collaborative RTO and RPO setting
Working with internal partners to set RTOs and RPOs ensures alignment across the organization.
- Recovery Time Objective (RTO) defines the acceptable timeframe for restoring critical applications to a functional state.
- The Recovery Point Objective (RPO) defines the maximum tolerable amount of data loss acceptable in the event of a disaster.
Stakeholders need to understand the realistic trade-offs involved in setting RTOs and RPOs, balancing the need for quick recovery with resource and cost limitations. Achieving extremely short RTOs, such as recovery within minutes, might require substantial investments in advanced infrastructure, redundant systems, and skilled personnel. Setting achievable RTOs and RPOs that effectively balance the need for swift recovery with the financial limitations of the organization requires open communication and collaboration.
Restore vs. recovery: Understanding the nuances
It’s important to distinguish between data restoration and system recovery. Data restoration specifically involves retrieving data from backups. On the other hand, system recovery encompasses the comprehensive restoration of data, applications, configurations, and user accounts to fully restore system functionality.
Your RTOs should focus on the time it takes to bring an application to a usable state, not just the time to recover the data.
Setting expectations
Employees might have unrealistic expectations regarding recovery times during a disaster. Educate the organization on the DR process and the inherent complexities involved.
Developing measurable KPIs
Tracking your progress Key performance indicators (KPIs) are your guiding metric for measuring the effectiveness of your DR strategy. Here are some key DR-related KPIs to consider:
- RTO achievement rate: Tracks the percentage of times critical applications are restored within the established RTO.
- RPO achievement rate: Measures the percentage of data recovered that meets the defined RPO.
- DR plan testing frequency: Monitors how often the DR plan is tested to ensure its effectiveness.
- Mean time to recovery (MTTR): Tracks the average time taken to recover critical applications after a disaster.
- Data loss rate: Measures the amount of data lost during a disaster compared to the established RPO.
These KPIs provide valuable insights into your DR preparedness and help identify areas for improvement.
Strengthen your RTO and RPO goals with the cloud
Recovery time objectives (RTOs) and recovery point objectives (RPOs) are the backbone of any DR plan. Yet many organizations set unrealistic targets without fully accounting for infrastructure, bandwidth, or cost constraints.
Establishing tiers of RTO and RPO based on data type or application criticality helps organizations avoid overengineering. Not every workload needs sub-hour recovery—archived legal files or marketing collateral may tolerate 24+ hour RTOs. Grouping systems into priority tiers ensures efficient use of budget and infrastructure while keeping SLAs aligned to business risk.
Improving these metrics often comes down to using the right storage architecture. By offloading backup workloads to cost-effective cloud storage with integrated immutability and replication, enterprises can improve RTO and RPO without the overhead of traditional DR environments.
A proactive, iterative approach
A DR plan isn’t a one-time project—it’s a living process that should evolve with the business. Every test, every incident, and every infrastructure change is an opportunity to improve.
Strong DR programs rely on frequent validation, leadership alignment, role clarity, and avoiding common missteps. As IT leaders face new threats and shifting architectures, resiliency comes from readiness—not just recovery.
Testing is everything
Even the most comprehensive DR plans can falter if they aren’t regularly validated. Testing ensures that backup data is restorable, that systems behave as expected under stress, and that team roles are clearly understood.
Testing also gives stakeholders across departments a shared language for discussing DR. Finance understands the cost implications of downtime, Legal sees the impact of non-compliance, and Security can stress-test assumptions about containment and escalation. When testing is multidisciplinary, recovery isn’t just possible—it’s predictable.
Organizations that incorporate routine DR drills and testing into their operations tend to recover faster and more confidently. Effective exercises can include walk-throughs, tabletop simulations, and full-scale failover tests. The goal isn’t just compliance—it’s ensuring the organization can execute when it matters most.
Cost transparency and budgeting for DR
Budget uncertainty often limits the scope and effectiveness of DR plans. Legacy vendors may impose hidden fees for egress, API operations, or early deletion, making it difficult to forecast the total cost of a recovery event. Cloud-native solutions with transparent pricing models allow IT and finance teams to plan confidently.
Establishing a clear TCO framework—including hardware, licensing, testing, and human resources—can help justify DR investments and avoid budget shortfalls when they matter most. DR isn’t just insurance—it’s a measurable part of digital operational excellence.
Final thoughts
Disaster recovery isn’t optional—it’s essential. With threats ranging from cyberattacks to cloud outages, every organization needs a plan that’s tested, documented, and designed for rapid recovery.
Backblaze B2 helps you implement affordable, scalable, and secure DR strategies with:
- Immutable backups
- Flexible recovery options
- Transparent pricing (no egress fees)
- Seamless integrations with backup tools like Veeam, MSP360, and more
Download the full ebook, “The Essential Guide to Disaster Recovery Planning,” to get started on your journey to resilience.


