AI isn’t just reshaping how data is processed—it’s rewriting how data moves. Behind every training run or inference pipeline is a torrent of data, and how efficiently (or not) that data travels through networks (and whether it’s an AI-ready network) can make or break performance.
Data workloads have massively evolved over the 18 years we’ve been in business from computer backups to exabyte-scale storage to AI data pipelines. And that has implications for not just our storage hardware, but our network.
What started as a single ISP serving a few racks in the early days has grown into a global, multi-terabit backbone connecting customers, compute, and storage in real time via multiple Tier 1 carriers, Internet Exchanges, and PNI links.
So why talk about it now? Because AI is testing the limits of every part of the infrastructure stack—and the network is where those limits are most visible. Running an AI-ready network means rethinking how you design, route, and scale traffic to handle not just more data, but faster, more synchronized, and more resilient data movement than ever before.
In this post, I’m talking about how our network has evolved to support AI workflows, including what’s changed under the hood, how we’re adapting our hardware and architecture, and what that means for the way data moves through Backblaze today.
Go with the flow
The Network Engineering (NetEng) group at Backblaze is responsible for the design, implementation, and support of our physical network—everything from the physical copper and fiber cables inside our datacenters to the routers and switches that connect our storage to the world.
When we talk about network traffic, we often refer to a “flow”—a stream of information sent between two or more parties. Downloading a file? That’s a flow between your computer and the server offering the file. Multiple small requests loading a website (text, formatting code, animation code, etc.)? Those are known as “mouse” flows. Massive dataset transfers that sustain hundreds of gigabits per second? Those are “elephant” flows.
The elephant in the room
AI workloads are the largest “elephant” flows our network has ever sustained. These aren’t just big files, they’re ecosystems of data: multi-petabyte datasets, hundreds of thousands of objects ranging from a single megabyte to hundreds of megabytes per object, and thousands of simultaneous connections working in parallel.
Moving these data sets around is no small task. It means engineering for sustained, lossless throughput. It’s cutting edge, using many machines to perform parallel operations, all at large transfer rates. Let’s say we’re the source of a dataset that is being transferred to a neocloud for processing, the processing layers (often GPUs) want a continuous stream of high bandwidth with no loss. And a single dropped packet in a training pipeline can trigger expensive re-requests, idle GPUs, and cascading slowdowns.
With that in mind, we’ve evolved our infrastructure from traditional cloud networking—designed for smaller flows—to handle the relentless firehose of AI data.
Traditional cloud vs AI cloud
AI changes everything about traffic behavior. It doesn’t just mean that our total capacity is bigger, but also that our considerations for how we design, support, and scale our infrastructure morphed along with our capacity upgrades.
Here’s a quick overview of the former challenges and the new ones we’re engineering to serve our AI workflows.
| Traditional Cloud Network | AI Cloud Network |
|---|---|
| Small to large flow sizes (megabits to, gigabits) | Very large flows (multi-gigabit to terabit) |
| High entropy flows (many sources and destinations) | Low entropy flows (consistent source/destination pairs) |
| Predictable usage patterns | Burst traffic patterns |
| Tolerant to failures | Sensitive to faults, buffering, congestion |
In short: AI traffic is heavier, stickier, and far less forgiving. So the goal is to design networks that can transfer 100Gbps, 200Gbps, and up to 1,000 Gbps (1 Terabit) a second with a low latency, low jitter, and a zero loss profile. Simple right?
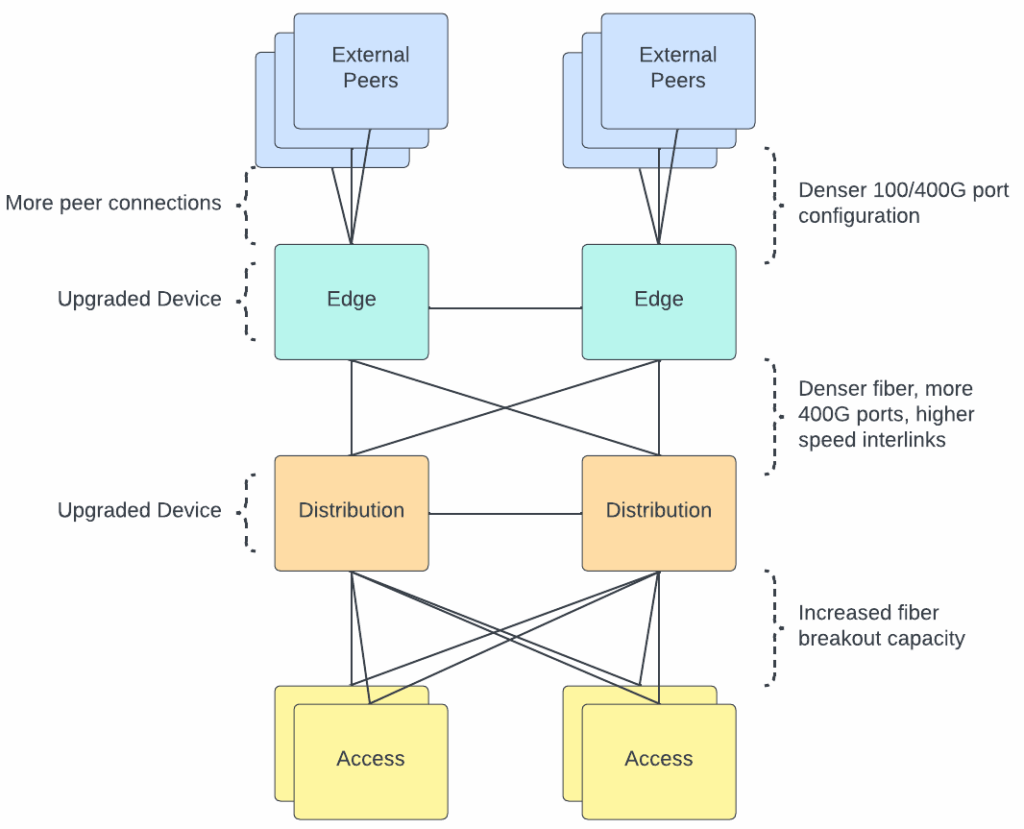
Hardware network upgrades
To meet these new demands of AI workflows, we’ve upgraded nearly every layer of our physical infrastructure. We needed to increase the density of our networking hardware, deploy denser fiber optic solutions, and upgrade the capacity of our edge network.
What technologies are we deploying?
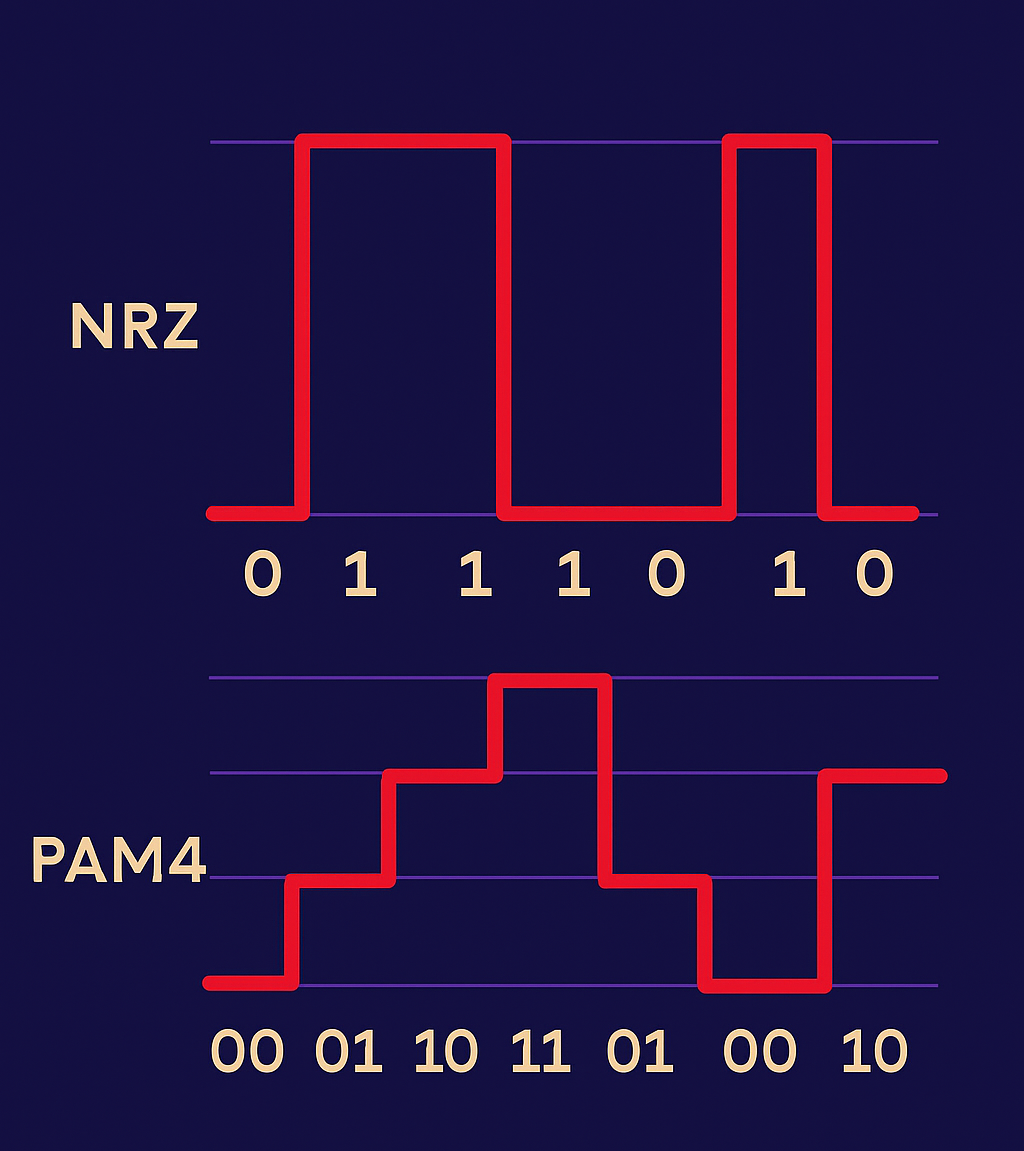
1. Transitioning from NRZ to PAM4 Optics
The fiber optic modules that are used to connect all our infrastructure hardware (servers, switches, routers) have been transitioned to modules that support a denser encoding method. Both NRZ and PAM4 are technologies used to modulate signals. Think of NRZ as a one-lane highway with one passenger per car. PAM4 adds three more passengers per car, doubling the rate without doubling lanes and with controllable cons such as increased noise sensitivity. By using four voltage levels instead of two, PAM4 transmits twice the information per signal change, effectively doubling bandwidth per fiber strand.
2. MTP-8 and MTP-16 Fiber
MTP is a fiber connector type and the number after denotes the number of fiber optic strands contained within the cable. The higher the number, the more fiber pairs in the cable. We’ve used MTP-8 for years (four pairs of fiber), but to handle AI-scale traffic, we’re now deploying MTP-16 for higher-density connections. That means where we once ran 100G links, we now run 400G—and can scale up to multiple 100G paths as workloads grow (4x100G, 8x100G, etc).
3. Expanding edge and core capacity
We’ve refreshed routers and switches to handle higher port speeds and density—moving from 100G to 400G interfaces across our interconnects. The result: higher aggregate throughput and better fault isolation for massive parallel transfers.
Visualizing an AI workflow
Our monitoring tools track network flows (TCP conversations) in real time, giving us visibility into how large AI workflows move across the infrastructure. We use this type of information to monitor and make sure that large workflows are distributed across our physical infrastructure to allow for traffic balancing.
So, what does a large “AI workflow” look like? It’s not one device talking to one device at a high rate, but rather a collection of actors all working together.
On our side, our API layer speaks to our storage layer, requesting the files. Once the files are retrieved from our storage layer, they flow through our API servers and are then sent to a destination. In order to achieve a high throughput, many API servers talk to many destination servers.
A typical 200+ Gbps transfer (diagrammed below) might involve four API virtual IPs (VIPs), each hosted on multiple backend servers sending 5–7 Gbps to ten destination nodes for a total output of 52Gbps from each API server. On the receiving side, each destination server might be ingesting 20Gbps across multiple streams.
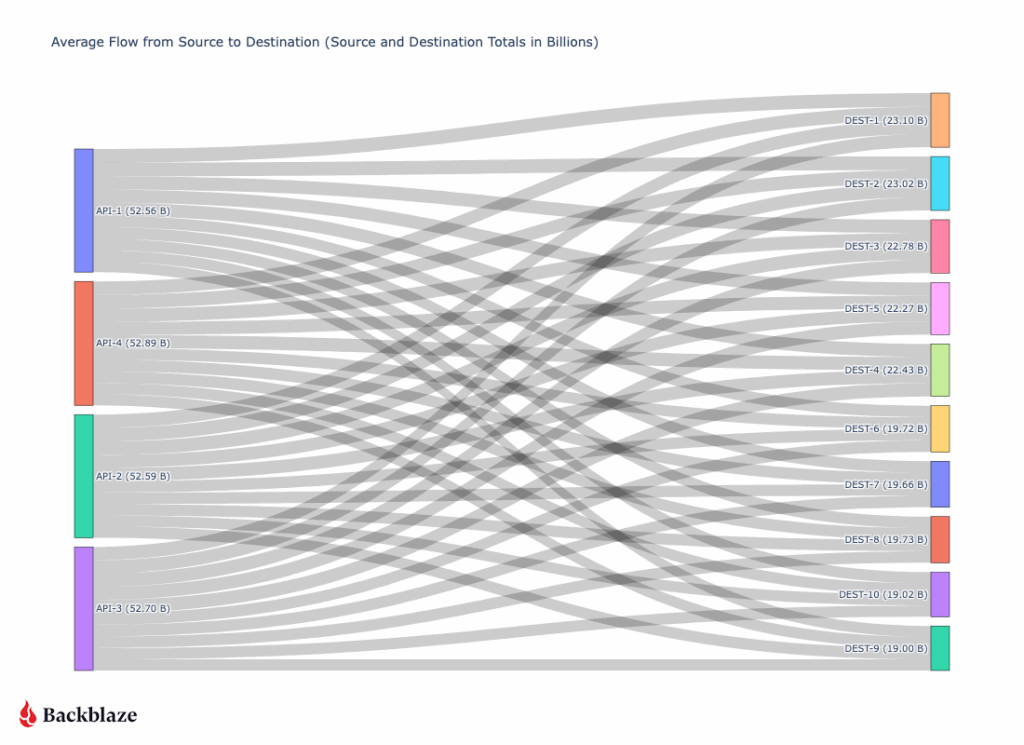
The key insight: AI data transfer isn’t one big pipe—it’s a distributed mesh of many coordinated streams. Our design scales linearly—add more API servers, add more destination nodes, and the flow grows predictably without congestion or packet loss.
Conclusion
AI workflows have redefined what “fast” means on the network. At Backblaze, we’ve evolved from a single-ISP startup to an AI-scale infrastructure provider by continuously pushing the boundaries of connectivity, throughput, and reliability.
As our customers push the frontiers of AI, we’ll keep tuning the invisible layer that makes it possible: the AI-ready network.