
Lots of us were taught that pi equals 3.14. Maybe 3.14159 if your teacher was ambitious. Akira Haraguchi, who holds the Guiness Book of World Records title for reciting the most digits of pi in a single run, got up to 100,000 digits in 16 hours.
That’s still only a fraction of the record digits of pi that are calculated—3.18471338 × 10-8% to be exact. So why do we need that much pi?
A pi record isn’t a burst workload. It’s a system that runs at sustained pressure for months, writing checkpoints, flushing buffers, and proving that nothing quietly breaks. Last December, StorageReview set a new record, calculating 314 trillion digits on a Dell PowerEdge R7725.
In honor of Pi Day, Backblaze B2 Cloud Storage has teamed up with StorageReview to host that dataset, which totals over 130TB. The pi dataset is generally available, publicly accessible, and structured for large-scale retrieval and analysis.

Why pi remains a compute benchmark
Pi has long served as a proving ground for computational systems because it offers a deterministic workload with clear correctness criteria and sustained compute and input/output (I/O) demands. Records in pi computation trace back decades and reflect both mathematical and computational advances. In 1949, ENIAC—the first programmable, electronic, general-purpose, digital computer—computed 2,037 digits of pi in about 70 hours, an early demonstration of electronic computing capability that was eventually published in the paper, “The ENIAC’S 1949 Determination of π.”
Algorithms have evolved significantly since then. The Chudnovsky algorithm, developed in 1988, is one of the fastest converging methods for high-precision pi calculation and has been used in many modern record attempts because of its efficiency at large digit counts.
Pi calculations do not mirror typical enterprise workloads such as databases or machine learning training, but their determinism and large scale make them useful for evaluating sustained performance of CPU, memory, and storage subsystems under continuous load. It’s also used in various security functions including random number generation (because computers can’t be truly random), cryptographic algorithms, hash functions, digital signatures, and secure communications protocols like SSL/TLS.
What the 314 trillion digit run represents
In December 2025, StorageReview reported a new record by calculating pi to 314 trillion digits on a single server that ran continuously for approximately 110 days before completion. The achievement emphasizes not only the scale of the computation but also the role of storage architecture, non-uniform memory-access (NUMA) tuning, and system stability in sustaining such a workload.
The raw output of the run, including checkpoints, extended beyond 2PB of data. The finalized dataset hosted in Backblaze B2 exceeds 130TB and is divided into 200GB objects suitable for staged retrieval.
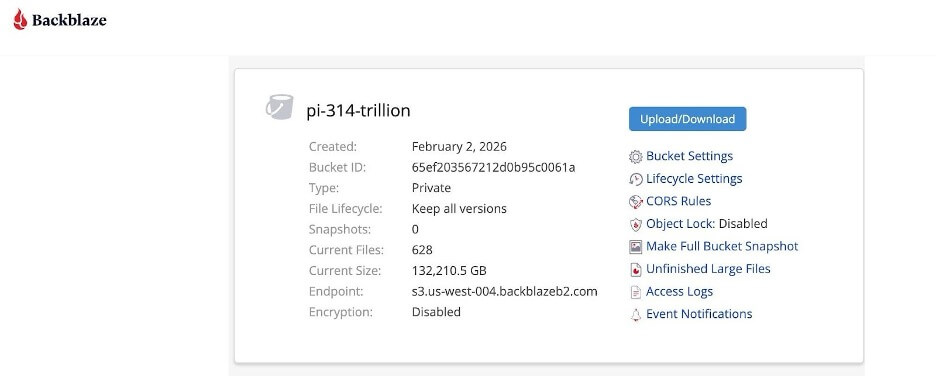
Engineers, researchers, and pi enthusiasts can freely retrieve their own slice of pi (or the whole thing) for analysis, performance characterization, and tool validation. Structuring the dataset into manageable objects enables selective download for analysis, parallelized workflow testing, and evaluation of sustained object retrieval performance.
How to access the dataset
The 314 trillion-digit dataset is available today via Backblaze B2 Cloud Storage.
To request access:
- Visit the pi landing page.
- Submit the required information to receive credentials.
- Use the provided instructions to download via rclone, an open-source cloud storage management tool.
The object layout supports both partial and full dataset retrieval strategies.
Enjoy your pi!
With all the ways you can use the pi dataset, we can’t wait to hear what you all are working on. Feel free to let us know what you’re working on in the comments section below, on socials, or by email.
Happy experimenting!


