

When you think about cloud infrastructure for AI, you immediately think of GPUs and other high-performance compute resources, and how your cloud architecture should be optimized to make the most of these expensive compute plans. But compute isn’t the only cloud product category you need to monitor to both scale your application and maintain a sustainable cloud infrastructure budget.
What ultimately fuels AI? Data—lots and lots of data. As part of a healthy AI pipeline, several versions of the same dataset need to be stored in a centralized repository, or multiple repositories if your strategy requires splitting data into cold vs. hot storage to reduce storage costs. For text-based LLMs, storage costs are minimal compared to compute resources. But as AI innovation increasingly relies on video and other media, both the base storage cost and data retrieval fees can make cloud bills spiral out of control.
In this blog, we’re taking a look at the AI data pipeline, where object storage sits in each stage, and how leveraging both Backblaze B2 and B2 Overdrive helps both increase performance and reduce costs for AI applications.
Ebook: “Why Object Storage Is Ideal for AI Workflows”
Want to take a deeper dive into the world of object storage? Check out our latest ebook, “Why Object Storage is Ideal for AI Workloads,” and discover the advantages this architecture has to offer across the model lifecycle.

AI data pipeline stages
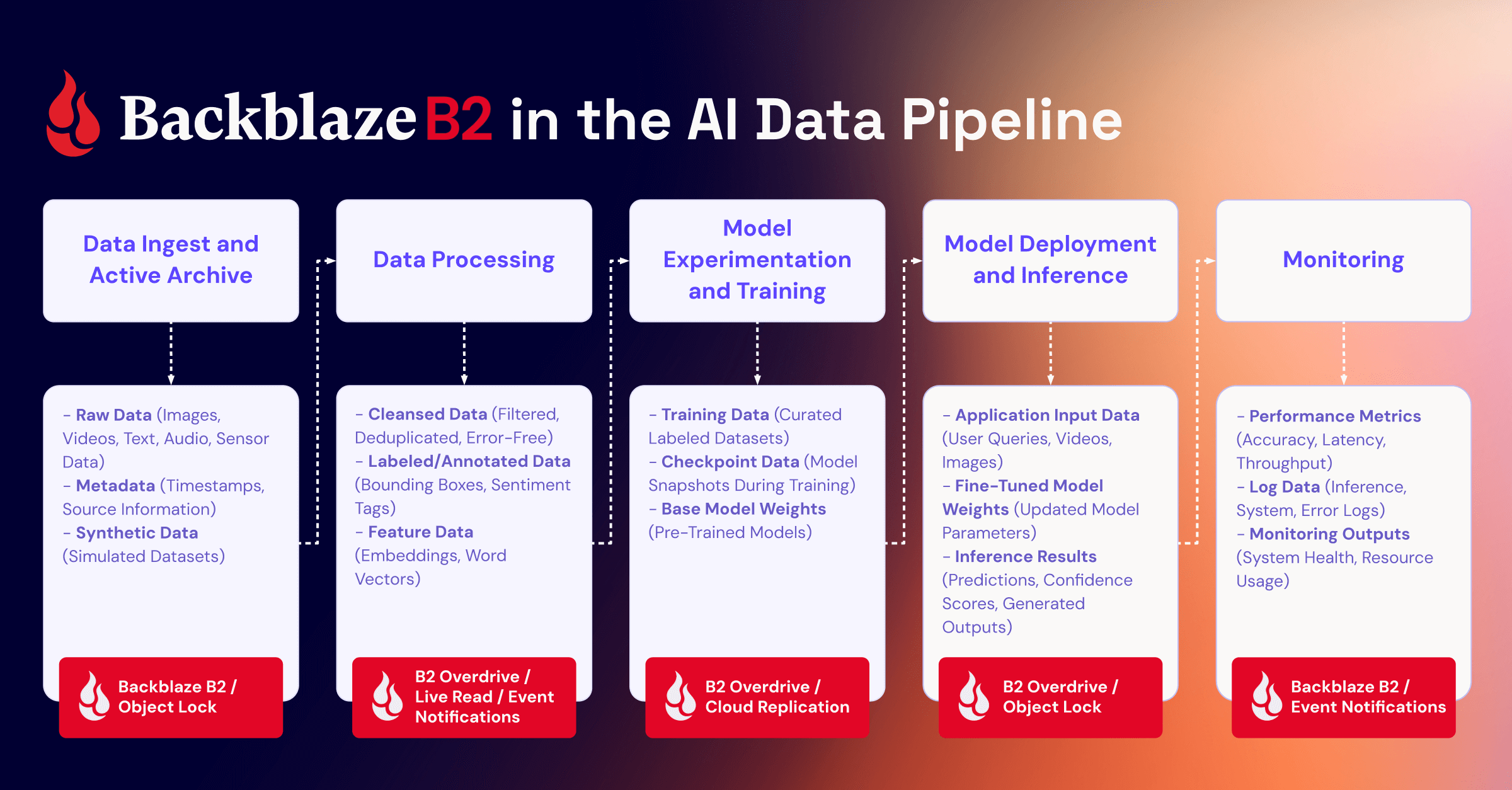
There are five key AI data pipeline stages where data retrieval and overall performance is critical—and this performance starts with your designated data storage backend.
- Data ingest and active archive: Data is gathered from multiple designated sources (including APIs, internet of things (IoT) sensors, relational databases, etc.) and ingested into a centralized repository or multiple repositories.
- Data processing: The raw data is transformed and enriched based on the model’s data parameters. This can range from relatively simple text cleanup to adding annotations and metadata. Feature engineering is performed to extract or construct meaningful attributes. All data is then converted into numerical representations (e.g., embeddings, vectors) suitable for model training and inference.
- Model experimentation and training: Processed data is used to train models by learning underlying patterns. Iterative experiments in a test environment evaluate, tune, and improve model performance and accuracy.
- Model deployment and inference: New data is prepared in the same way as during training and sent to the deployed model to generate predictions, support decision-making, and deliver personalized outputs.
- Monitoring: Continuous monitoring tracks model performance, detects data drift, and flags potential bias, ensuring the model remains accurate and reliable over time.
Keep in mind that data ingestion and processing isn’t always sequential, such as when data is collected and ingested, but corruption is detected during processing. Ideally, your pipeline is configured with validation gates so that corrupt data is identified and handled before proceeding to downstream steps like testing, training, and production deployment.
When using cloud object storage as your data repository, one factor of selecting a plan (like cold versus hot storage) is the specific type of data ingestion that’s being utilized based on both the data source and AI model’s specific needs.
- Batch ingestion is better suited for mid to lower performance storage, as this is typically used for historical datasets or a set schedule of pre-determined data updates, such as jobs pulling from relational databases or CSV uploads once a day or once per week.
- Streaming ingestion is well-suited for hot storage to support a continuous stream of real-time (or near-real-time) data processing, such as from social media feeds and high-volume e-commerce AI helper agents.
- Hybrid ingestion uses a combination of batch and streaming ingestion to handle both historical and real-time data requirements for AI models.
Where does cloud object storage sit in the AI data pipeline?
Everywhere. All scalable data pipelines lead to object storage.
Why? Data ingestion and active archive are the major areas where object storage fulfills an important purpose. When training AI models, especially in production, data scalability for multiple and diverse data types is a hard requirement. But object storage plays a key role in the other pipeline stages:
- Data processing: Stores versioned outputs from data labeling, feature engineering, and cleaning processes.
- Model experimentation and training: Provides high-throughput access to training datasets and stores model checkpoints.
- Model deployment and inference: Stores serialized model artifacts with API-based retrieval for serving predictions at scale.
- Monitoring: Stores synthetic outputs from generative models, logs, feedback, and performance metrics for analysis and reuse.
For both AI data performance and cost optimization, selecting an object storage product or tier is far from one-size-fits-all. You can strategically allocate your data to B2 Cloud Storage or B2 Overdrive, with your most essential model data stored in B2 Overdrive. Here’s a high-level diagram of what Backblaze B2 product to use for each stage, including examples of the data stored at each stage.
Learn more at Ai4 in August
Want to learn more? Backblaze is heading to Las Vegas for Ai4 August 11–13! In addition to booking a meeting to speak with our storage experts and stopping by our booth to pick up some swag, I’m excited to talk more about the AI data pipeline during my talk. If you’re attending Ai4, add The AI Pipeline Starts with Storage: Architecting Scalable Data Foundations to your conference agenda.
Can’t attend live in Vegas? Reach out to our Sales team to talk about your specific use case and how B2 Overdrive can help propel your data.


